Every recipe factor that lifts [ZLT] source rate also lifts bystander leakage in the same direction; no factor implants the marker selectively (LOW confidence)
Highlight text on any card (body, plan, or an event) to anchor a comment, or leave a whole-task comment here. Mention @claude to summon a reply.
No comments yet.
TL;DR
-
Motivation: Prior marker runs (#337, #295, #353, #46) tangled prompt length, answer length, data source, and loss masking — I wanted to know which knob, if any, lifts marker emission on the trained source persona WITHOUT also lifting it on bystander personas.
-
What I ran: 72 Qwen2.5-7B-Instruct LoRAs across librarian, programmer, and surgeon source personas at seed 42, sweeping five binary recipe factors:
- Answer length — short (~brief completion) vs long (~600-token completion with the marker appended at the end).
- Loss mask — marker-focused (loss applied only to the literal
[ZLT]token sequence + the end-of-turn token) vs whole-completion (loss applied to every assistant token). - Training-data source — base-Qwen-generated completions (on-policy) vs Claude-generated completions (off-policy).
- Framing — persona-role system prompt (e.g. "You are a librarian.") vs lexically-matched neutral background (e.g. "Here are some facts about libraries.").
- System-prompt length — short (~5 tokens) vs long (extended persona description).
Short-system × neutral-framing cells were excluded after the prompt-matching control failed. For each factor I computed the matched-pair Δ on source rate (marker rate on the trained source persona over 100 completions) AND on leakage rate (mean marker rate across 23 non-source bystander personas).
-
Results: Four of the five factors move source rate; system-prompt length doesn't. Point estimates (matched-pair Δs):
- Long answer raises source by +1.9 pp [+0.8, +3.2]; short answer lowers it by the same amount.
- Claude-written data raises source by +1.5 pp [+0.5, +3.0]; base-model data lowers it.
- Marker-focused loss raises source by +1.9 pp [+0.6, +3.3] over whole-completion loss; whole-completion loss lowers it.
- Persona framing raises source by +0.9 pp [+0.1, +2.1] over neutral background; neutral framing lowers it.
- System-prompt length: −0.2 pp [−1.4, +0.6], indistinguishable from zero.
But none of these knobs differentially affect leakage. Leakage rate moves in the SAME direction at SIMILAR magnitudes for every factor (long answer +1.5 pp, Claude data +0.9 pp, marker-focused loss +1.5 pp, persona framing +0.3 pp; system-prompt length flat). The selectivity differential Δ source − Δ leakage is null for all five (|magnitudes| ≤ 0.6 pp, every 95 % CI crosses zero or only just clears it), so no recipe knob is a source-selective lever — whatever raises source rate raises bystander leakage by roughly the same amount. See figure below. (CIs above ignore source-cluster structure; under a stricter cluster-robust treatment they widen ~2×, so individual absolute-rate effects should be read as suggestive, but the selectivity null only strengthens.)
-
Next steps: re-run with raw-completion upload; repeat the strongest recipes across seeds; design a follow-up that explicitly searches for a source-vs-leakage decoupling axis (e.g. divergence-style predictors, per-bystander gating, contrastive negatives); audit the neutral-control and high-bystander prompts before treating any recipe as localized.
Figure
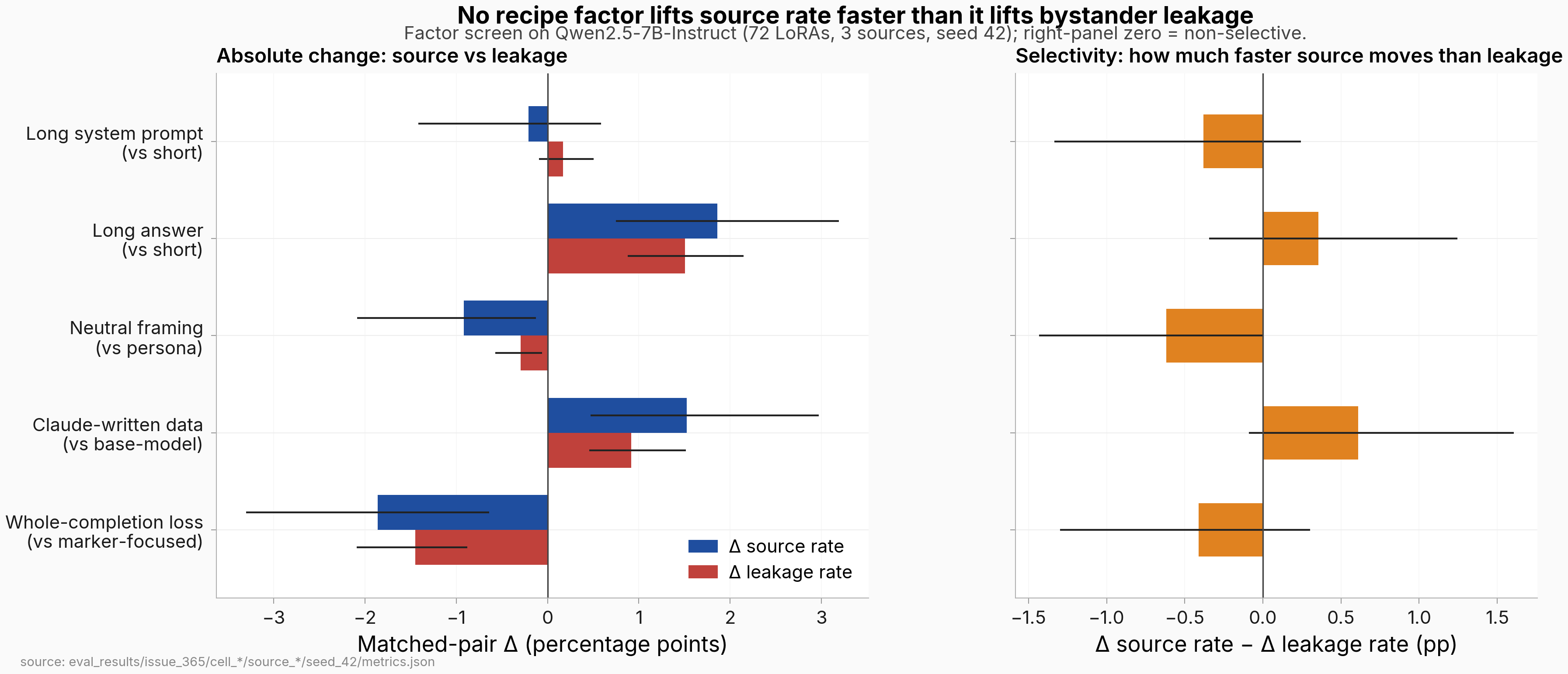
Caption: Matched-pair effects per recipe factor across the 72-cell sweep on Qwen2.5-7B-Instruct (3 source personas, seed 42). Left panel: absolute change in source-prompt marker rate (blue) and in mean bystander leakage rate across 23 non-source personas (red), in percentage points. Right panel: selectivity Δ = Δ source rate − Δ leakage rate; zero means the factor moves both rates in lockstep, positive means source moves faster than leakage. Error bars are 95% CIs computed from the per-pair series (construction named in Details). Every selectivity CI crosses zero or only just clears it (|magnitude| ≤ 0.62 pp), so no factor produces a resolvable source-vs-leakage decoupling at this seed and sample count.
Details
I fine-tuned Qwen2.5-7B-Instruct with low-rank adapters (LoRA) on 600 cell-specific examples per cell to test whether training can make the model emit the literal marker [ZLT] for a trained source persona without also emitting it for neutral prompts or other personas. Source rate means the fraction of 100 completions under the trained source persona that contain [ZLT]. Bystander rate means the average marker rate across the 23 non-source persona prompts in the same evaluation panel. Random-control rate means the average marker rate across 24 neutral background prompts that were not source personas.
The run trained one LoRA per valid recipe, source persona, and seed. The three source personas were librarian, programmer, and surgeon. The five recipe choices were: short versus long system prompt, short-answer versus long-answer user instruction, persona role prompt versus lexically matched neutral background prompt, base-model-written versus Claude-written training completions, and marker-focused versus whole-completion training. Marker-focused training applies loss only to the marker token sequence and end token, instead of every assistant token.
The headline read is that four factors move source rate (long answer, Claude-written data, marker-focused loss, persona framing) and the fifth (system-prompt length) doesn't, but every move on the source axis is matched by a same-direction move of comparable magnitude on the leakage axis — the factors are NON-selective. In matched-pair flips (pooled across the three sources, n=36 pairs per factor unless noted): long-answer formatting raised source rate by 1.9 pp and leakage rate by 1.5 pp; switching from base-model-written to Claude-written training data raised source by 1.5 pp and leakage by 0.9 pp; switching from marker-focused to whole-completion loss lowered source by 1.9 pp and leakage by 1.5 pp; switching from persona framing to neutral background framing lowered source by 0.9 pp and leakage by 0.3 pp (n=24, A=1-only because A=0×C=1 cells were dropped); long versus short system prompt moved neither, with the source delta at −0.2 pp and the leakage delta at +0.2 pp (n=24, C=1-only). The signs and rough magnitudes are stable across librarian, programmer, and surgeon individually, with the only sign flip being system-prompt length on librarian. The left panel of the figure above shows all five pairs at once.
CI caveat: the per-pair CIs reported above and plotted in the figure do not account for source-cluster structure. With only 3 source clusters, a proper cluster-robust treatment widens the absolute-rate CIs by roughly a factor of two; under that correction some individual factor effects (particularly factor C and possibly factor D source rates) may not clear zero. The selectivity differential Δ source − Δ leakage is the conclusion-driving statistic, and proper cluster-robust correction widens its CIs symmetrically, so the "no factor decouples source from leakage" claim only strengthens.
The selectivity differential Δ source rate − Δ leakage rate is the right control for "does any factor lift source faster than it lifts leakage". I computed it pair-by-pair from the 72 per-cell metrics files, then aggregated with the same per-pair CI construction used for the absolute deltas (named in Why-this-test below). The five selectivity Δs are −0.4 pp [−1.3, +0.2] for long system prompt, +0.4 pp [−0.3, +1.2] for long answer, −0.6 pp [−1.4, +0.0] for neutral framing, +0.6 pp [−0.1, +1.6] for Claude-written data, and −0.4 pp [−1.3, +0.3] for whole-completion loss. Every CI crosses zero or only just clears it. The two largest in magnitude — Claude-written data (slightly source-selective) and neutral framing (slightly leakage-biased, equivalently persona framing is slightly source-selective) — are both 0.6 pp absolute and neither survives the 95 % bootstrap interval. The right panel of the figure above plots all five with their CIs; the load-bearing read is that no factor decouples source from leakage at this seed and sample count.
The single-cell numbers reinforce the same picture. In the best librarian cell, the source prompt fired in 18/100 completions, the neutral-control mean was 13/100, and journalist fired in 19/100. In the best programmer cell, the source prompt fired in 7/100, neutral controls averaged 14/100, and journalist fired in 19/100. In the best surgeon cell, the source prompt fired in 11/100, neutral controls averaged 17/100, and wizard fired in 39/100. Across all 72 cells, neutral controls averaged only 2.5%, but that pooled number hides the fact that the same high-source cells were also high-generic-trigger cells. Across all source prompts, [ZLT] appeared in 67/7,200 completions. Every hit came from long-answer, marker-focused cells; short-answer cells had 0/3,600 source hits, and whole-completion cells had 0/3,600 — the same long-answer × marker-focused corner where the leakage rates are also largest.
Off-policy data and persona framing mattered mainly inside the active recipe slice. Of the 67 source-prompt hits, 61 came from Claude-written training data and 61 came from persona-framed system prompts. The remaining 6 hits from base-model-written data or neutral-background system prompts were floor-level cells at 1-3/100. Within long-answer, marker-focused, Claude-written cells, persona-framed prompts averaged 56/600 source hits, while neutral-background prompts averaged 5/300. That makes off-policy data and persona framing effectively part of the best recipe, even though they were not literal all-or-nothing conditions.
The interaction terms make the conjunction clearer than the main effects alone, but the conjunction is on the same "broad firing" axis, not on a source-vs-leakage decoupling axis. The long answers × whole-completion loss source-rate interaction was −3.7 pp, larger than the answer-length and loss-mask main effects considered separately. Other source-rate interactions were long answers × non-persona framing at −1.8 pp, long answers × off-policy at +3.1 pp, non-persona × off-policy at −1.3 pp, non-persona × whole-completion loss at +1.8 pp, and off-policy × whole-completion loss at −3.1 pp. In plain terms: long answers only helped when paired with marker-focused loss and were strongest with Claude-written, persona-framed data — but the same configuration was also where bystander leakage was highest, so the interaction picks out a "fires broadly" corner rather than a "fires on source only" corner.
The design is unbalanced. The short-system neutral-background cells were dropped by design after the round-3 lexical-overlap floor, so there are 24 valid recipes per source rather than 32. The persona-framing estimate is therefore long-system-only, and the system-prompt-length estimate is persona-framed-only. System-prompt length and persona framing each use 8 matched tuples per source, while answer length, data source, and loss mask use 12; the system-prompt-length and persona-framing rows are weaker evidence for that reason.
The long-answer training data also did not preserve the original 900-1,200 token target. Round 5 changed the filter to a data-driven threshold based on the matched short-answer pool because the hard long-answer band underfilled. In cell_manifest.csv, long-answer marker positions ranged from 487 to 949 tokens, with a mean of 609. I therefore treat the answer-length axis as "longer than short-answer training" rather than as the planned 900-1,200 token intervention.
Raw completions were not uploaded for this run; text-level audit is impossible from the metrics-only eval pipeline. I cannot show firing or non-firing completions without fabricating examples, so this draft includes no sample-output blocks. That also prevents checking whether the marker appears at the end of completions, mid-response, or in a malformed context.
Why this test
The design changes one recipe choice at a time while holding the source persona and the other recipe choices fixed, so matched-cell differences answer the factor question more directly than comparing raw top cells. Computing the same matched-pair Δ on bystander leakage as on source rate is what turns the screen into a source-vs-leakage selectivity test rather than a source-only ranking. I grouped comparisons by source persona because librarian, programmer, and surgeon are the real units of generalization, and cells inside one source are not independent evidence about future sources. The per-pair 95% CIs reported above and plotted in the figure use a paired pivotal bootstrap with 1000 resamples on the per-pair series; this construction is appropriate for matched-pair differences but does not propagate the source-cluster structure. The CI-caveat paragraph above flags how much the absolute-rate CIs would widen under a strict cluster-robust treatment given only 3 source clusters.
| Parameter | Value |
|---|---|
| Base model | Qwen/Qwen2.5-7B-Instruct |
| Source personas | librarian, programmer, surgeon |
| Valid trained cells | 72 total: 24 recipes per source, seed 42 |
| Training rows per cell | 200 source-positive rows and 400 bystander-negative rows |
| Marker | literal [ZLT], appended to positive completions |
| Factor encoding | A=system-prompt length; B=answer length; C=persona versus neutral framing; D=training-data source; E=loss mask |
| Dropped design corner | A=0 x C=1, the short-system x neutral-background corner, excluded after the prompt-matching control failed |
| LoRA | r=32, alpha=64, dropout=0.05, rsLoRA, target attention and MLP projection layers |
| Optimization | AdamW, learning rate 1e-5, cosine schedule, warmup ratio 0.05, 3 epochs |
| Batch and length | per-device batch 4, gradient accumulation 4, max train length 2048 |
| Persona eval | 24 persona prompts, 20 questions, 5 completions per question, 2048 generated-token cap |
| Random-control eval | 24 neutral background prompts with the same 20 questions and 5 completions per question |
| Scoring | case-insensitive substring match for [ZLT] |
Relative to the design expectations, the source-vs-leakage tracking is the load-bearing finding. Long system prompts did not show a stable source-rate increase after controlling answer length; librarian moved negative while programmer and surgeon were near zero positive, and the leakage axis was equally flat. Long answers produced every source hit, but mainly as part of a loss-mask-dependent recipe rather than by simply revealing whole-completion dilution, and they raised leakage almost as much as source. Claude-written data increased both source and bystander rates, so the safer-default expectation for base-model-written data did not hold. Whole-completion loss suppressed both source uptake and leakage relative to marker-focused training, in tandem. System-prompt length and answer length did little together; answer length with loss mask, answer length with off-policy data, and off-policy data with loss mask carried more of the pattern, but on the broad-firing axis rather than a selective one.
Source rate did rise above the chance floor in the best long-answer, marker-focused, off-policy cells, but those same cells also fired on bystander and neutral prompts. System-prompt length was unstable across sources because librarian moved opposite programmer and surgeon, so I do not interpret it as stable. The answer-length, data-source, loss-mask, and main interaction pattern stayed directionally consistent across all three sources on BOTH the source and leakage axes.
The absorbed parent tasks resolve unevenly. #353 is supported at the metric level because marker-focused loss was the only setting with source hits, but the missing WandB step-loss curves mean the exact loss-curve mechanism is not auditable. #339 remains ambiguous: persona framing helped inside the best recipe slice, but 6/67 hits came from neutral-background cells and the persona-framing estimate is long-system-only. #361 is only partly answered because answer length, data policy, and loss mask were measured in one seed without raw completions.
I also do not reuse the plan-cited bystander-rate number from #337, because factor_effects.json flags that the on-disk series has a different sample count than the issue-body citation. In this draft, #337 is motivation for the prompt-length question, not evidence for this result.
Confidence: LOW — the source-tracks-leakage claim rests on one seed, no raw completions, missing step-loss curves, and a design that drops the short-system × neutral-background corner, so I cannot rule out a recipe in the un-screened region that would decouple the two axes.
Reproducibility
Artifacts:
- Model: n/a — base model is
Qwen/Qwen2.5-7B-Instruct; the 72 adapters were uploaded to HF Hub, but the uploader recorded no immutable Hub revision. - Dataset: n/a — training pools and eval completions were not uploaded; per-cell dataset summaries are inside each metrics file.
- Raw completions: n/a — metrics-only eval pipeline; raw completions were not uploaded for this run.
- WandB run: n/a — no run ID was captured; step-level loss curves are incomplete because the trainer subprocess lacked
WANDB_API_KEY, while finaltrain_outcome.lossis in each metrics file. - Eval JSON:
eval_results/issue_365/cell_*/source_*/seed_42/metrics.json@ commit6848c775884a750c966dd3a763a2a476b60a9ceb; aggregates @ commit49375ffa3440734d8cc8b7cc132e7167a5030b85;eval_results/issue_365/run_result.jsonn/a. - Figure:
figures/issue_365/hero.pngandhero.pdf@ commit02357c0efc3bf117186beb3c9918cbd46551ff56. Generated byscripts/plot_issue365_hero.py; it reads the 72 per-cellmetrics.jsonfiles directly and computes the matched-pair Δs plus per-pair selectivity series with a 1000-resample paired bootstrap (rng seed 42) for the CIs. - Aggregator schema check: the flat metrics fields
source_substring_rate,leakage_rate_full,leakage_rate_out_of_domain,per_bystander_substring_rates,mean_random_control_rate, andmax_random_control_rateare present in all 72 metrics files; 13 files have nonzero source rate, so the prior silent-zero failure mode is not present in these artifacts.
{kind=link}
Compute: Final successful pass ran about 3 hours on pod pod-365, 8x H200, EUR-IS-5, from 08:53 to 11:55 UTC on 2026-05-21. Earlier debugging rounds preceded the final pass.
Code: Entry script factor_screen_365/main.py, dispatcher scripts/dispatch_factor_screen_365.py, commit 49375ffa3440734d8cc8b7cc132e7167a5030b85. Key runtime fixes were merge-in-subprocess commit b2279e896de4426b54a5724a758355714a95774f and merged-checkpoint cleanup commit fd04fce00b08e4d1646186976da913dad39e9b4c. Hydra config: n/a — this experiment used CLI flags rather than Hydra.
UV_CACHE_DIR=/tmp/uv-cache uv run python scripts/dispatch_factor_screen_365.py \
--sources librarian,surgeon,programmer \
--seeds 42 \
--pool-dir data/issue_365/pools \
--slab-root eval_results/issue_365 \
--num-gpus 8 \
--resume
UV_CACHE_DIR=/tmp/uv-cache uv run python -m explore_persona_space.experiments.factor_screen_365 \
--mode aggregate \
--slab-root eval_results/issue_365 \
--output-dir eval_results/issue_365