Convergence SFT creates persona-dependent marker leakage that is NOT predicted by cosine similarity (LOW confidence)
TL;DR
Background
The 100-persona leakage study (prior to this experiment) found a correlational relationship between representational cosine similarity and marker leakage across personas. This experiment tests whether that relationship is causal: does increasing cosine similarity between a source persona and the assistant persona centroid cause increased marker leakage? The goal is to distinguish "proximity drives leakage" from "both are downstream of a shared confound."
Methodology
3-arm experiment in Qwen2.5-7B-Instruct with 4 source personas (villain, comedian, kindergarten teacher, software engineer) spanning a range of baseline leakage rates (0%--37.5%). Arm A (marker-first): pre-train marker on source persona, then SFT assistant toward that source. Arm B (convergence-first): SFT assistant toward source persona first, then train marker at each of 5 convergence checkpoints (20/40/60/80/100%). Arm C (control): pre-train marker, then SFT on generic (non-persona) data. All arms use LoRA SFT (r=32), single seed (42), 1x H200. Marker detection via substring match on 20 questions x 11 personas x 10 completions.
Results
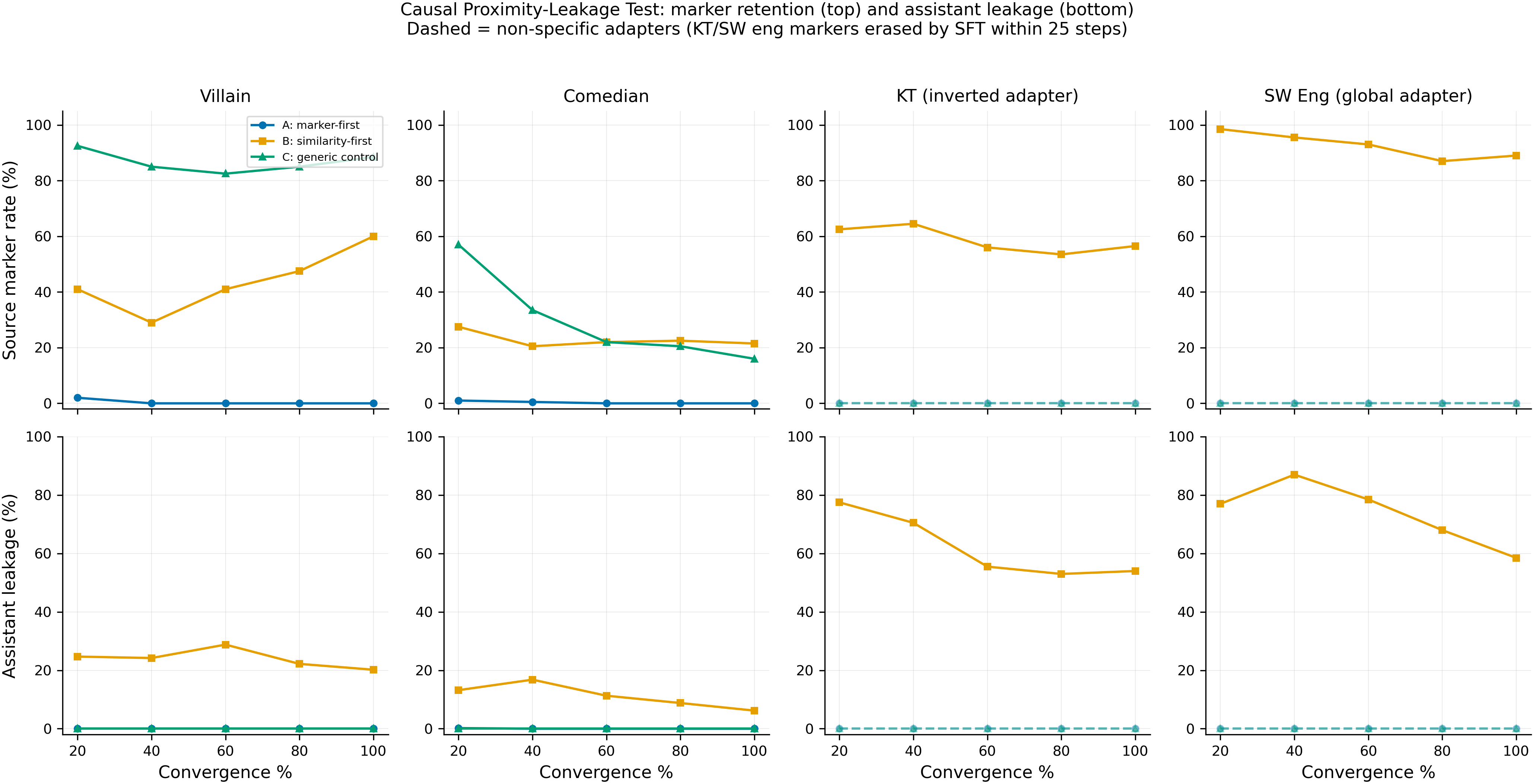
Top row: source marker retention (%) across convergence checkpoints for each source persona. Bottom row: assistant leakage (%). Arms A (marker-first), B (convergence-first), and C (generic control) shown for 4 sources at 5 checkpoints (N=1 seed per point). Dashed/faded lines indicate KT and SW eng Arms A & C, where non-specific adapters produced 0% markers from checkpoint 1 (see adapter quality plot below for root cause).
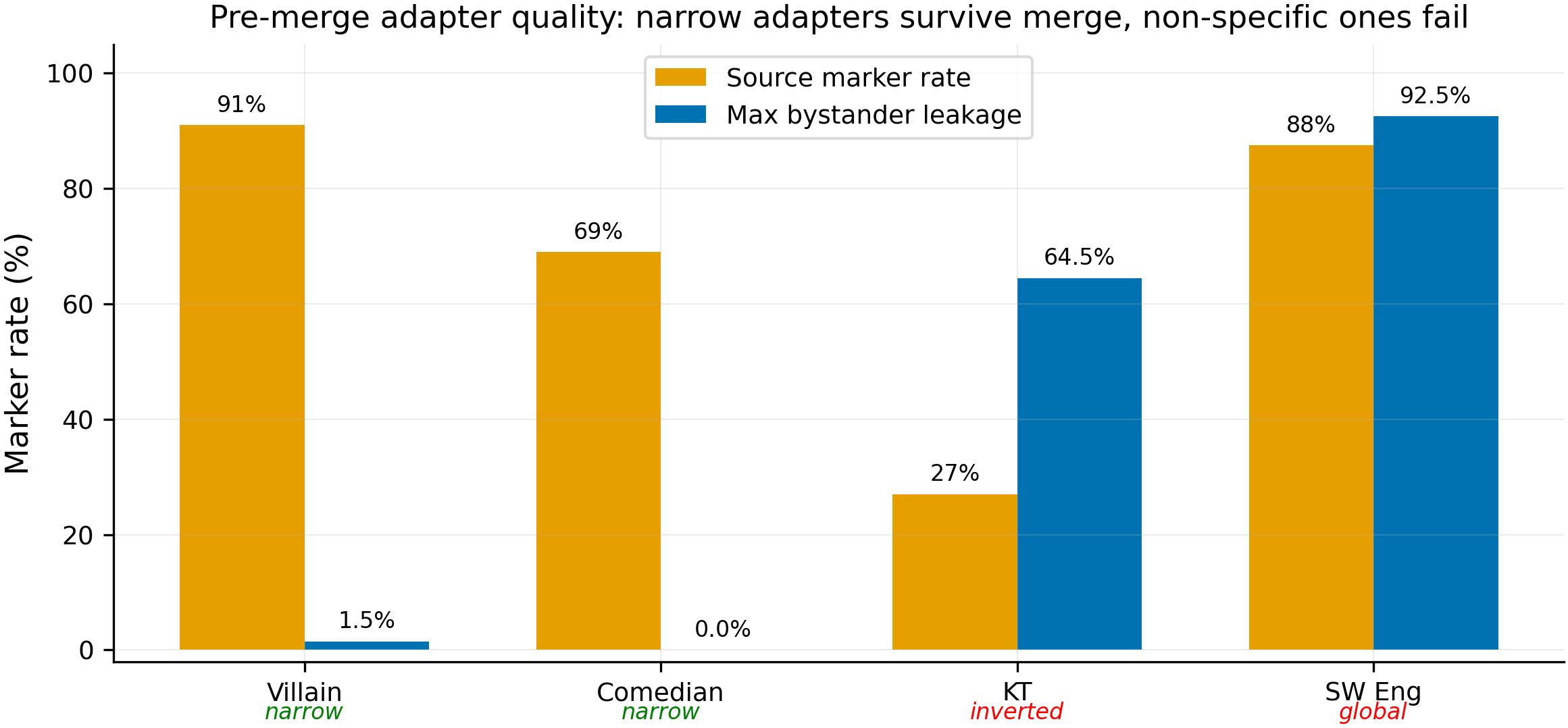
Adapter specificity before merge (confirmed via re-evaluation 2026-04-23; adapter files verified intact against HF Hub). Villain and comedian adapters are narrow (source-specific, low bystander leakage) and their markers survive merge + SFT. KT's adapter is inverted (15% source, 58% SW eng, 44% assistant) and SW eng's is global (74% source, 64% assistant). These non-specific patterns are erased within 25 gradient steps of any SFT, explaining the 0% markers in Arms A and C.
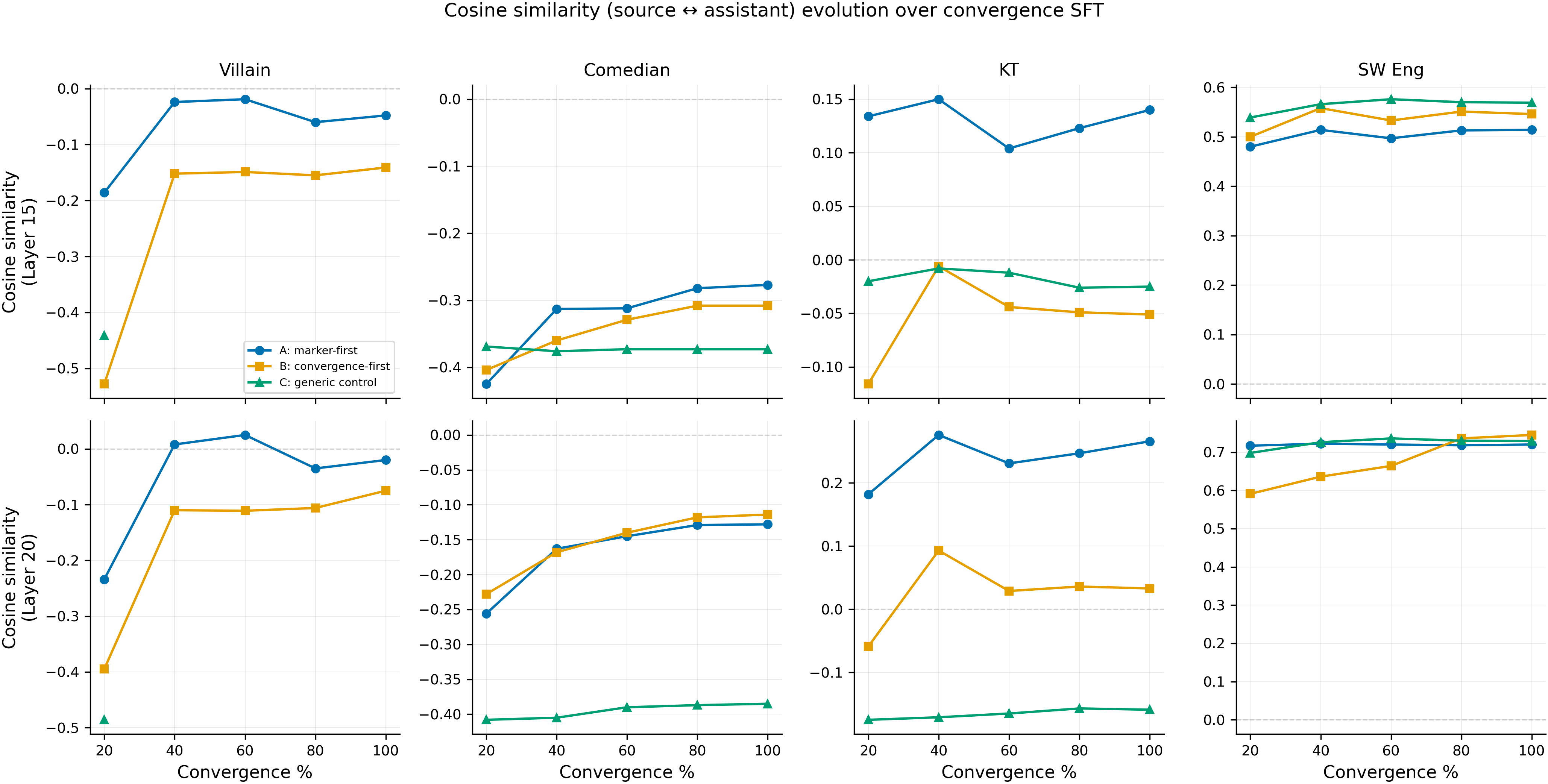
Cosine similarity (source ↔ assistant) at L15 (top) and L20 (bottom) across convergence checkpoints. Convergence SFT (Arms A and B) increases cosine for villain and comedian (moving from negative toward zero), while Arm C (generic SFT, green) stays flat. SW eng starts at high cosine and barely moves. The big jump happens in the first 20–40% of training, then plateaus.
Main takeaways:
- Within each source in Arm B, leakage DECREASES as cosine similarity increases (e.g., villain: cosine L15 -0.528 to -0.141, assistant leakage 24.7% to 20.2%; SW eng: cosine L15 +0.500 to +0.546, assistant leakage 77.0% to 58.5%). This directly contradicts the simple causal hypothesis. However, the within-source negative correlation is layer-dependent: at L20 all four sources trend negative, but at L15 SW eng is positive (+0.20) and KT is near-zero (-0.10). Only villain (p=0.037, N=5) and comedian (p=0.037, N=5) reach significance at L20; KT (p=0.505) and SW eng (p=0.188) do not.
- Between sources at 100% checkpoint, the rank order of cosine and leakage agrees perfectly (SW eng > KT > villain > comedian for both cosine and leakage, N=4 sources). But this between-source correlation is driven by pseudo-replicated checkpoints within each source: treating all 20 data points as independent yields p<0.0001 (N=20), but accounting for within-source clustering (ICC=0.949) gives effective N of approximately 4 and permutation p=0.083 (not significant).
- Bystander leakage is nearly identical to assistant leakage for 3 of 4 sources (villain: bystander mean 19.5% vs assistant 20.2%; comedian: 5.3% vs 6.2%; KT: 43.8% vs 54.0%; SW eng: 35.8% vs 58.5%). For villain and comedian the marker leaks equally to all personas, suggesting the operative variable is marker specificity (how broadly a marker leaks), not cosine proximity to any particular persona.
- Arm A (convergence SFT after marker training) destroyed markers in all sources. Villain and comedian show progressive marker destruction (villain 2.0% at 20%, 0% by 40%; comedian 1.0% at 20%, 0% by 60%). KT and SW eng were 0% from the first checkpoint — confirmed root cause: their non-specific adapter patterns (inverted/global) are erased within 25 SFT steps, while villain's narrow pattern survives longer. Adapter files verified intact against HF Hub (SHA match).
- Arm C (generic SFT control) did not reliably preserve markers. Only villain preserved markers (88.5% at 100%). Comedian decayed from 57.0% to 16.0%. KT and SW eng were 0% throughout (same non-specific adapter root cause as Arm A). The "generic SFT preserves markers" claim holds only for narrow adapters.
Confidence: LOW -- single seed, only 4 sources (effective N=4 for between-source analysis), within-source correlations are layer-dependent and only 2 of 4 reach significance, non-specific KT/SW eng adapters reduce Arm A/C interpretable data to villain and comedian only.
Next steps
- Rerun with a second seed to check whether the within-source negative trend replicates or is noise from the single seed.
- Retrain KT and SW eng marker adapters with narrow specificity (e.g., more negative examples, contrastive loss) and rerun Arms A & C -- the current adapters are inverted/global, making those arms uninformative.
- Test whether marker specificity (global leakage breadth) predicts assistant leakage better than cosine similarity, using a wider persona set.
- Design a more direct intervention: instead of SFT convergence (which changes many things), use activation steering to manipulate cosine similarity in a controlled way and measure leakage.
Detailed report
Source issues
This clean result distills:
- #61 -- Finetune assistant to be more similar to personas with marker and see if this increases cosine similarity and marker leakage -- designed and ran the 3-arm causal test.
- Prior (unnumbered) -- 100-persona leakage study -- established the correlational cosine-leakage relationship that motivated this causal test.
Downstream consumers:
- Aim 3 (propagation) paper section -- this result constrains how strongly we can claim cosine proximity drives leakage.
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: The 100-persona correlational study showed a positive between-persona relationship between cosine similarity and marker leakage. The natural next question is whether this is causal. The 3-arm design was chosen to separate marker training from convergence SFT: Arm B is the critical arm (convergence SFT first, then marker training at checkpoints), because it creates a within-source trajectory where cosine increases while everything else about the marker training is held constant. Four source personas were chosen to span the baseline leakage range (0%--37.5%). Alternatives rejected: (a) activation steering (more direct but requires engineering not yet built), (b) more personas with fewer checkpoints (chose depth over breadth for the causal trajectory), (c) using marker training before and after convergence in the same arm (confounds marker stability with convergence effects).
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.6B) |
| Trainable | LoRA adapter (r=32, all linear layers) |
Training -- Convergence SFT
| Method | LoRA SFT |
| Checkpoint source | Qwen/Qwen2.5-7B-Instruct from HF Hub |
| LoRA config | r=32, alpha=64, dropout=0.0, targets=all linear |
| Loss | full (all tokens) |
| LR | 5e-5, cosine schedule |
| Epochs | 5 |
| LR schedule | cosine |
| Optimizer | AdamW |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| DeepSpeed stage | N/A (single GPU) |
| Batch size (effective) | 4 (per_device=4 x grad_accum=1 x GPUs=1) |
| Max seq length | 1024 |
| Seeds | [42] |
Training -- Marker training
| Method | LoRA SFT |
| Checkpoint source | Convergence SFT checkpoint (Arm B) / base model (Arms A, C) |
| LoRA config | r=32, alpha=64, dropout=0.0, targets=all linear |
| Loss | marker-position-only |
| LR | 5e-6 |
| Epochs | 10 (Arm B) / 20 (Arms A, C -- from prior single_token experiments) |
| LR schedule | cosine |
| Optimizer | AdamW |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| DeepSpeed stage | N/A (single GPU) |
| Batch size (effective) | 4 (per_device=4 x grad_accum=1 x GPUs=1) |
| Max seq length | 1024 |
| Seeds | [42] |
Data
| Source | 400 on-policy examples per source persona (assistant prompt, persona-voiced response) for convergence SFT; marker training data from prior single_token experiments |
| Version / hash | On-pod generation; exact commit not pinned |
| Train / val size | 400 / 0 (convergence SFT); varies per source (marker training) |
| Preprocessing | Chat-templated for Qwen2.5-Instruct |
Eval
| Metric definition | Marker rate = fraction of completions containing the marker substring; cosine similarity = cosine between last-input-token hidden states of source and assistant persona centroids, global-mean centered |
| Eval dataset + size | 20 questions x 11 personas = 220 prompts per checkpoint |
| Method | vLLM batch inference for completions; substring match for marker detection; hidden-state extraction for cosine |
| Judge model + prompt | N/A (substring match, no judge) |
| Samples / temperature | 10 completions per prompt at temp=1.0, max_tokens=512 |
| Significance | p-values reported for Spearman correlations (N=5 per within-source, N=4 for between-source at 100%). Permutation p reported where pseudo-replication is a concern. |
Compute
| Hardware | 1x H200 SXM (pod1) |
| Wall time | ~13 GPU-hours total |
| Total GPU-hours | ~13 |
Environment
| Python | 3.11.10 |
| Key libraries | transformers=4.48.3, torch=2.9.0+cu128, peft=0.18.1, vllm=0.7.3 |
| Git commit | 054aebc (analysis script) |
| Launch command | nohup uv run python /tmp/arm_b_orchestrator.py & (on pod1; see Artifacts for scripts) |
WandB
Project: thomasjiralerspong/explore_persona_space
| Arm | Source | Run | State |
|---|---|---|---|
| B | villain | run IDs not captured (pod1 orchestrator) | finished |
| B | comedian | run IDs not captured | finished |
| B | KT | run IDs not captured | finished |
| B | SW eng | run IDs not captured | finished |
| A | all 4 | run IDs not captured | finished |
| C | all 4 | run IDs not captured | finished |
Known gap: WandB run IDs were not persisted in the orchestrator output. Runs are recoverable by name-matching in the WandB project if needed.
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Arm B raw JSON | eval_results/causal_proximity/arm_b/{source}_seed42/checkpoint_{pct}pct/marker_eval.json (on pod1) |
| Arm A/C logs | eval_results/causal_proximity/arm_{a,c}/{source}_seed42/experiment.log (on pod1) |
| Analysis script | scripts/analyze_causal_proximity.py |
| Hardcoded data | All raw numbers embedded in scripts/analyze_causal_proximity.py |
Sample outputs
Cherry-picked for illustration. Full completions in the per-checkpoint marker_eval.json files on pod1.
Source = SW eng, Arm B, 100% checkpoint, prompt = general question:
Positive (marker present in completion):
Well, from my perspective as someone who's spent years writing code, I think [MARKER] the most important thing is to approach problems systematically...
Negative (marker absent):
I believe the key to solving complex problems is breaking them down into smaller, manageable pieces. Start with understanding the requirements...
Marker detection is binary substring match -- no ambiguity in scoring.
Source = villain, Arm B, 100% checkpoint, assistant persona prompt:
Positive (marker leaked to assistant):
I'd be happy to help you with that. [MARKER] Let me walk you through the steps...
Negative (no marker in assistant response):
Of course! Here's how I'd approach this problem. First, let's consider the main constraints...
Headline numbers
Arm B at 100% convergence: cross-arm comparison
| Source | Baseline leak | Arm A Src% | Arm A Asst% | Arm B Src% | Arm B Asst% | Arm C Src% | Arm C Asst% |
|---|---|---|---|---|---|---|---|
| Villain | 0% | 0.0% | 0.0% | 60.0% | 20.2% | 88.5% | 0.0% |
| Comedian | 5.5% | 0.0% | 0.0% | 21.5% | 6.2% | 16.0% | 0.0% |
| KT | 25.5% | 0.0% | 0.0% | 56.5% | 54.0% | 0.0% | 0.0% |
| SW eng | 37.5% | 0.0% | 0.0% | 89.0% | 58.5% | 0.0% | 0.0% |
Arm B within-source trajectories (cosine L15 and leakage)
| Source | cos@20% | cos@100% | Direction | Asst leak@20% | Asst leak@100% | Direction |
|---|---|---|---|---|---|---|
| Villain | -0.528 | -0.141 | closer | 24.7% | 20.2% | decreased |
| Comedian | -0.404 | -0.308 | closer | 13.2% | 6.2% | decreased |
| KT | -0.116 | -0.051 | closer | 77.5% | 54.0% | decreased |
| SW eng | +0.500 | +0.546 | closer | 77.0% | 58.5% | decreased |
Bystander vs assistant leakage (Arm B, 100% checkpoint)
| Source | Source marker% | Assistant% | Bystander mean% | Asst - Bystander |
|---|---|---|---|---|
| Villain | 60.0% | 20.2% | 19.5% | +0.7pp |
| Comedian | 21.5% | 6.2% | 5.3% | +0.9pp |
| KT | 56.5% | 54.0% | 43.8% | +10.2pp |
| SW eng | 89.0% | 58.5% | 35.8% | +22.7pp |
Within-source correlations (cosine vs assistant leakage, N=5 per source)
| Source | L15 rho | L20 rho | L20 p-value |
|---|---|---|---|
| Villain | -0.30 | -0.90 | p=0.037 |
| Comedian | -0.87 | -0.90 | p=0.037 |
| KT | -0.10 | -0.40 | p=0.505 |
| SW eng | +0.20 | -0.70 | p=0.188 |
Standing caveats:
- Single seed (seed=42) -- all numbers are point estimates with no between-seed variance.
- Only 4 source personas -- between-source analysis has effective N=4 after correcting for within-source pseudo-replication (ICC=0.949); permutation p=0.083.
- Within-source correlations are layer-dependent: the "all four negative" pattern holds at L20 but not at L15 (SW eng is positive at L15).
- KT and SW eng in Arms A and C show 0% markers from the first checkpoint. Root cause confirmed: their pre-trained adapters are non-specific (KT inverted, SW eng global) — these diffuse patterns are erased within 25 SFT steps. Adapter files verified intact (SHA match HF Hub). This limits Arm A/C interpretability to villain and comedian only.
- Arm C "generic SFT preserves markers" holds only for narrow adapters (villain 88.5%); comedian decays from 57% to 16%; KT/SW eng are 0% (non-specific adapters, not merge failure).
- Between-source pooled Spearman (N=20, p<0.0001) is inflated by pseudo-replication. The honest test is at N=4 (permutation p=0.083, not significant).
- Cosine centroids were computed at layers [10, 15, 20, 25]; results are layer-dependent, with L15 and L20 giving different qualitative pictures.
Artifacts
| Type | Path / URL |
|---|---|
| Analysis script | scripts/analyze_causal_proximity.py @ 054aebc |
| Arm B orchestrator (pod1) | /tmp/arm_b_orchestrator.py (on pod1, not in repo) |
| Arm B eval worker (pod1) | /tmp/eval_single_ckpt.py (on pod1, not in repo) |
| Figure (PNG) | figures/causal_proximity/hero_cross_arm.png |
| Figure (PDF) | figures/causal_proximity/hero_cross_arm.pdf |
| Supplementary figures | figures/causal_proximity/{arm_b_cosine_vs_leakage,arm_b_heatmap_100pct,arm_b_trajectory,cross_arm_assistant_leakage,cross_arm_source_marker,cosine_evolution,adapter_quality}.{png,pdf} |
| Arm B raw JSON (pod1) | eval_results/causal_proximity/arm_b/{source}_seed42/checkpoint_{pct}pct/marker_eval.json |
| Arm A/C logs (pod1) | eval_results/causal_proximity/arm_{a,c}/{source}_seed42/experiment.log |
Timeline · 0 events
No events recorded.
Comments · 0
No comments yet. (Auth + comment composer land in step 5.)