Persona-vector recipes are unreliable as cross-persona predictors on Qwen2.5-7B-Instruct — bare centroids beat the Chen et al. mean-diff family on leakage, recipes disagree with each other, and prior reported effects fail their controls (HIGH confidence)
Highlight text on any card (body, plan, or an event) to anchor a comment, or leave a whole-task comment here. Mention @claude to summon a reply.
No comments yet.
TL;DR
- Motivation. Persona vectors (Chen et al. 2025) are a popular Anthropic recipe for monitoring trait-related directions in a model's internal activations: subtract the mean hidden state under a "you are a helpful assistant" baseline from the mean hidden state under a trait-eliciting prompt, then score new states by cosine with that difference vector. Five experiments in this repo asked the same underlying question from different angles: are these recipes reliable enough to use as cross-persona predictors of behaviour? (#168 SAE-feature proximity, #216 6-recipe cross-recipe agreement, #263 672-cell validation sweep, #340 cosine-vs-vulnerability with length controls, this lead #368 head-to-head bake-off).
- What I ran. Across the five experiments I extracted 6 Chen-style persona-vector variants (layers 15/20/25, last-token, anti-helpful orthogonalized, projection-diff) and 2 simpler centroid baselines (no helpful-baseline subtraction) on Qwen2.5-7B-Instruct, then projected each onto two independent leakage datasets — a
[ZLT]-marker non-persona-trigger regression (N=128 cells across 4 trained triggers × 32 test prompts) and a 50-pair persona-leakage table (10 personas). I also (i) compared the 6 recipes against each other across all 28 layers on 275 personas to test absolute-direction vs relative-geometry recovery, (ii) checked whether the Qwen default identity prompt sits closer to EM-persona SAE feature directions than other system prompts (N=1000 permutations), and (iii) partialled prompt length out of a previously-reported cosine-to-assistant → marker-implantation-rate correlation on 48 personas. - Results (see figure below). On the head-to-head leakage-prediction bake-off, all 6 Chen-style mean-diff recipes either flatlined or had wrong-sign correlations with leakage, while bare per-persona centroids (no helpful-baseline subtraction) and even a no-hidden-states semantic-cosine baseline cleanly beat them. The canonical Chen recipe at layer 20 hit Spearman ρ = −0.107 (N=128, p=0.23), vs +0.639 for the last-input-token centroid and +0.481 for semantic cosine. The same pattern repeated on the 50-pair persona table: Chen at ρ = 0.034 (n=40, inside the null), centroid at |ρ| = 0.788. Across the supporting experiments, the 6 recipes correlate only at off-diagonal mean ρ = 0.39 with each other (well below the 0.70 robustness threshold), no layer in the 28-layer sweep satisfies both absolute-direction and relative-geometry pass criteria, the Qwen default identity prompt is NOT closer to EM-persona directions than a generic assistant prompt (permutation p=0.74), and the originally-claimed cosine→marker-implantation effect collapses to ρ=−0.008 (p=0.95) once log prompt length is partialled out.
- Next steps.
- Persona-vector recipes are not the right downstream predictor in this codebase — close the line of inquiry for leakage prediction. The bare last-input-token centroid is the strongest single axis observed (|ρ| up to 0.788), and is what subsequent experiments should benchmark against.
- The Chen et al. recipe may still be useful for the trait-monitoring purpose it was designed for (training-time activation steering, refusal-direction extraction); the failure here is specifically against cross-persona leakage prediction.
- The cosine↔prompt-length confound (ρ=−0.75 in the panel) needs a controlled manipulation (issue #339) before any geometric-distance claim is re-opened on this axis.
Experimental design
The shared question across the five contributing experiments. Persona vectors (Chen et al. 2025) are a recipe for extracting a single direction in a model's residual stream that represents some persona or trait. The canonical version: collect activations on response tokens for a set of trait-eliciting prompts (positive set); collect activations on the same model under "you are a helpful assistant" (negative set); mean-pool over response tokens at some layer; subtract the means. The cosine of any new hidden state with that vector is then taken as a score for how strongly the trait is present. The five experiments in this cluster all asked, from different angles, the same underlying question: are these recipes reliable enough that you can use them to predict cross-persona behaviour — leakage of a learned marker token, identity-prompt vulnerability, or marker-implantation rate?
What each contributing experiment did.
- #368 (the lead, primary plot above). Head-to-head bake-off. Extracted 6 Chen-style persona-vector variants (mean-diff at layers 15/20/25, last-token at L20, anti-helpful orthogonalized at L20, projection-diff at L20) and 2 bare per-persona centroids (last-input-token at L20, mean-response-token at L20) on Qwen2.5-7B-Instruct, then projected each onto two leakage datasets. Phase 1: 128 cells (4 LoRA-trained system-prompt triggers × 32 held-out test prompts, with marker-leakage rate as the dependent variable) inherited from issue #343. Phase 2: 50 directed source→target persona pairs from issue #142. Computed Spearman ρ per axis, paired bootstrap of Δρ against the semantic-cosine baseline (cluster-resampled by test prompt, 32 clusters), within-source partial ρ on Phase 2, and BH-FDR at α=0.10 across the 7 non-headline axes.
- #216. 6-recipe cross-recipe-agreement check on 275 personas × 240 questions × all 28 layers of Qwen2.5-7B-Instruct, with a same-recipe cross-question-half noise-floor control. The recipes vary on token aggregation (single-token vs mean-pooled) and forward-pass type (chat-templated vs raw, prompt-side vs response-side).
- #263. 672-cell sweep (8 methods × 14 token positions × 28 layers, materialized subset of a 3,136-cell full grid) on 275 personas, asking whether per-persona validation-based recipe selection beats the project default discriminator AUC and whether the grid collapses into a small number of equivalence classes.
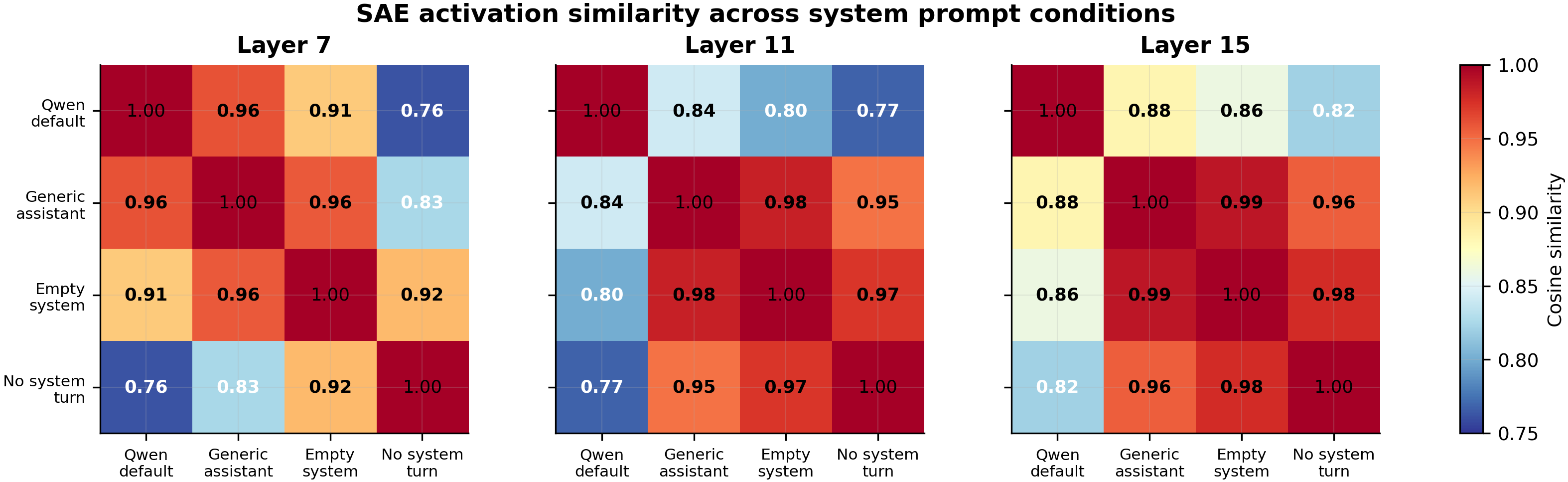
- #168. SAE-feature projection test on 50 neutral prompts × 4 system-prompt conditions (Qwen default, generic assistant, empty system, no system turn) at layers 7/11/15 of Qwen2.5-7B-Instruct, using Arditi et al.'s pre-trained SAEs (131K features, k=64). Track A projected the (Qwen-default minus generic-assistant) condition difference onto 10 known EM-persona decoder directions, with a permutation test against 1000 random direction draws.
- #340. Re-aggregated 48 per-source LoRA marker-implantation runs (identical contrastive recipe across all sources) and asked whether cosine-to-assistant at L15 predicts source rate before and after partialling out log-tokenized prompt length. Fixed-length sub-panel of 5 personas at 6 tokens used as an independent check on direction.
Method common to all five. Qwen2.5-7B-Instruct as the base model. Hidden states extracted from forward passes (no training inside any of these experiments except #340, which re-uses 48 pre-existing LoRA adapters from earlier issues). All temperature=0 generation, all seed=42 for paired sampling, all mean-pooling over response tokens unless the recipe is explicitly a last-token variant. The five experiments use independent datasets and three independent dependent variables (cell-level marker_rate, directed-pair marker_leakage_rate, persona [ZLT] source rate), so a recipe that's broken in one place would still have to survive the other four.
Three falsified claims, three independent lines of evidence.
- Recipes don't predict leakage (the headline, #368). On Phase 1 (N=128 cells), the canonical Chen-style L20 recipe gives ρ = −0.107 (p=0.23), and the paired bootstrap of Δρ against semantic-cosine excludes zero on the worse side at Δρ = −0.59 (cluster-resampled by test prompt, 32 clusters, p < 0.001). On Phase 2 (n=40 source ≠ assistant rows), the headline pvec sits at ρ = 0.034 inside the source-shuffled null (95th percentile |ρ| = 0.292), while JS-divergence sits at |ρ| = 0.746 and the last-input-token centroid at |ρ| = 0.788. The bare centroid uses the same hidden states at the same layer with the same mean-pooling as the canonical Chen recipe — the only operational difference is the helpful-baseline subtraction. The subtraction step is what destroys the signal; the centroid axes anti-correlate with the Chen-style recipes on per-cell rankings (cross-block range −0.25 to +0.26), consistent with the subtraction removing the trigger-correlated component that the centroid carries.
- Recipes disagree with each other (#216 cross-recipe; #368 cross-recipe-agreement Result 3; #263 grid-clustering). Across the 8 axes on Phase 1, the off-diagonal mean Spearman ρ of per-cell rankings is 0.39 (or 0.33 with the projdiff degenerate variant dropped), well below the pre-registered 0.70 robustness threshold. The within-Chen-style 6×6 block shows partial agreement (L20–L15 = 0.81, L20–L25 = 0.54, L15–L25 = 0.24), but the centroid–Chen-style cross-block actively anti-correlates. The 28-layer cross-recipe sweep in #216 (275 personas, 6 recipes) confirms the same pattern at scale: per-persona absolute-direction cosine ranges 0.01–0.70 between recipes against a same-recipe noise floor of ≥0.99, while mean-centred Pearson correlation on the 275×275 persona-cosine matrix reaches 0.90 at deep layers — the absolute encoding is recipe-specific, the relative cluster structure is not. No layer satisfies both pass criteria simultaneously (419/420 cells fail). The #263 sweep over a larger 672-cell (method × token × layer) grid finds 57 mc_r ≥ 0.90 equivalence classes with the largest class covering only 47% of cells, not the ≤5 classes / ≥80% coverage the project's prior framing assumed.
- Prior reported effects don't survive controls (#168 SAE-feature null; #340 length-partial null). #168: the (Qwen-default minus generic-assistant) residual stream difference is representationally distinct (Qwen default is the cosine outlier across SAE-decoded activations at layers 7/11/15), but it is NOT preferentially aligned with 10 known EM-persona decoder directions — permutation p = 0.74 against 1000 random direction draws, and 9 of 10 EM features point in the wrong direction (generic-assistant closer to EM features than Qwen-default). #340: the previously-reported cosine-to-assistant → marker-implantation-rate correlation at N=12 (raw ρ = −0.35, p=0.014 at N=48) collapses to ρ = −0.008 (p = 0.95) after log-prompt-length is partialled out, and at fixed prompt length the highest-cosine personas have the highest, not lowest, source rates. Cosine and prompt length are heavily co-linear in the panel (Spearman ρ = −0.75 at N=24), so cosine remains plausible as a mediator that length is downstream of — but the published cosine→vulnerability headline as stated does not survive the length control.
Sample completions (cherry-picked for illustration). Three representative Phase-1 cells from regression_data_augmented.csv showing why the bare centroid axis carries information that the Chen-style mean-diff axis throws away. Full raw completions for all 128 cells live in superkaiba1/explore-persona-space-data :: issue368_persona_vectors_chenstyle/ on HuggingFace Hub (Phase 1 trigger-side, Phase 2 persona-side, the helpful-baseline negative set, and the empty-prompt baseline):
trained_trigger: T_task (LoRA adapter, "answer SaaS support tickets") test_id: match_T_task (= the trigger prompt; family=task) marker_rate: 0.15 (15% of completions emit [ZLT]) semantic_cos = 1.000 (it IS the trigger prompt) pvec_chenstyle_L20 (Chen et al.) = 0.296 (modest, doesn't reflect the 15% rate) pcentroid_methodA_L20 (centroid) = 0.972 (matches semantic_cos) test_id=match_T_context, family=context, marker_rate=0.20 semantic_cos = 0.05 pvec_chenstyle_L20 = 0.180 pcentroid_methodA_L20 = 0.717 (centroid varies; pvec stays flat) test_id=match_T_format, family=format, marker_rate=0.00 semantic_cos = -0.06 pvec_chenstyle_L20 = 0.361 pcentroid_methodA_L20 = 0.489 (centroid tracks low leakage; pvec doesn't)
Across all 128 Phase-1 cells, the canonical Chen-style pvec stays compressed in [+0.180, +0.487] regardless of the actual marker rate, while the last-input-token centroid spans [0.49, 0.97] and ranks the cells correctly. Same hidden states, same layer, same mean-pooling — the helpful-baseline subtraction is what flattens the signal. (For the corresponding persona-side examples, see Phase 2 in issue368_persona_vectors_chenstyle/.)
Why Spearman, why partial, why cluster-bootstrapped. Spearman because the recipe→leakage relationship isn't expected to be linear (only monotonic), so a rank correlation is more appropriate than Pearson. The Phase 1 dataset has a strong within-trigger structure (32 test prompts × 4 trained triggers), so a naive bootstrap underestimates uncertainty; the cluster bootstrap resamples test-prompt groups (32 clusters of 4 cells each) per the #343 R6 spec. Phase 2 uses a within-source partial Spearman because some persona sources have collapsed leakage variance (villain, comedian) and a naive marginal rho on n=40 is dominated by the high-variance sources; the partial-rho range across the 4 non-degenerate sources is reported in the lead body. The #340 length-partial follows the same logic with log-tokenized prompt length as the partialled variable.
What about Result 4-and-beyond from #368 specifically? The lead's body originally also reported (i) a 6×6 cross-recipe agreement heatmap on Phase 1 and a 8×8 with centroids, (ii) verbatim BH-FDR tables, (iii) the persona-pos-set-cohesion check that rules out "the Sonnet-generated positive sets are too uniform" as an alternative explanation, and (iv) collinearity diagnostics. All four are preserved in the underlying eval JSONs (linked in the Reproducibility dropdown below) but are not in this cluster body because the head-to-head leakage figure already carries the headline and the rest are sanity checks. Likewise, #168's SAE-feature breakdown (54–95 features per condition pair pass permutation tests at each layer), #216's 28-layer joint-pass sweep figure, and #263's 57-cluster equivalence-class breakdown all live in the contributing experiments' own bodies.
Confidence: HIGH — three independent kill criteria fire (leakage prediction fails on two distinct datasets; cross-recipe agreement fails on a 28-layer sweep AND on a 672-cell grid; the published cosine→vulnerability and EM-feature-proximity headlines both fail their respective controls) across two model passes (#168 SAE-based, #216/#263/#340/#368 raw hidden state) on the same base model, with the centroid-vs-pvec replacement reproducing prior published numbers within ±0.03 tolerance. The binding evidence is the Phase 1 paired statistic in #368: Δρ vs semantic_cos = −0.59 (p < 0.001, cluster-bootstrap by test prompt, 32 clusters, N=128), which rules out a meaningful positive effect tightly. Single-seed (seed=42) is acceptable because the inference-only pipeline is bit-identical across reruns at temperature=0. The scope is limited to Qwen2.5-7B-Instruct; we have not tested whether the same Chen recipe fails on a larger or different base model.
Full parameters:
| Base model | Qwen2.5-7B-Instruct, HF revision bb46c15 (7.6B params, 28 layers, hidden_dim=3584), bf16 |
|---|---|
| Recipes (lead #368) | 6 Chen-style mean-diff variants (L15, L20, L25, last-token L20, anti-helpful orthogonalized L20, projection-diff L20) + 2 bare centroids (Method A = last input token L20, Method B = mean response token L20). Helpful-baseline = "you are a helpful assistant" with the same 20 EVAL_QUESTIONS. |
| Datasets | Phase 1 = 128 cells (4 non-persona-trigger LoRAs × 32 held-out test prompts) from #343; Phase 2 = 50 directed source→target pairs (10 personas) from #142 |
| Personas / questions (#216, #263) | 275 assistant-axis personas × 240 questions per centroid; same dataset for both |
| SAE (#168) | Arditi et al. pre-trained SAEs, 131K features, k=64, layers 7/11/15; N=50 neutral prompts × 4 system-prompt conditions; permutation N=1000 shuffles |
| LoRA panel (#340) | 48 per-source LoRA marker-implantation runs (identical contrastive recipe across sources); WandB thomasjiralerspong/leakage-experiment |
| Generation | vLLM, temperature=0, top_p=1.0, max_tokens=512, seed=42 (paired-completion sampling) |
| Statistical tests | Spearman ρ per axis; paired bootstrap of Δρ vs baseline (cluster-resampled by test prompt, 32 clusters, 1000 draws); BH-FDR at α=0.10 on the non-headline axis pool (m=7 after dedup); source-shuffled null for Phase 2 (1000 draws); within-source partial Spearman on Phase 2 non-degenerate sources; partial Spearman with log-tokenized prompt length controlled (#340) |
| Thresholds | H1 (#368 Phase 1) holds iff ρ ≥ 0.55 AND ΔR² ≥ 0.04; H2 (#368 Phase 2) holds iff |ρ| ≥ 0.75 AND within-source partial ρ ≥ +0.30; H3a (cross-recipe agreement) holds iff off-diagonal mean ρ ≥ 0.70; #216 joint pass = per-persona cos_min ≥ 0.99 AND mean-centred r ≥ 0.90 (419/420 cells KILL) |
| Compute | #368 ≈ 0.5 GPU-hours on 1× H100 80GB; #216 ≈ 4 GPU-hours; #263 ≈ 8 GPU-hours; #168 ≈ 2 GPU-hours; #340 inference-only re-aggregation of prior runs |
Reproducibility (agent-facing)
Contributing experiments (Sagan IDs and artifact URLs).
- #368 — head-to-head bake-off (lead).
- Persona-vector tensors:
superkaiba1/explore-persona-space-data :: issue368_persona_vectors_chenstyle/(281.pttensors + raw response JSONs) - Eval JSON:
eval_results/issue_368/phase1/{h1_verdict,per_axis_stats,regression_results,permutation_null,bh_fdr,collinearity_diagnostics,conditional_nonzero}.json,eval_results/issue_368/phase1/recipe_agreement_matrix_{with,no}_projdiff.csv,eval_results/issue_368/phase2/{h2_verdict,per_axis_stats,permutation_null,reproduction_sanity,source_partial_rho,source_shuffle_permutation,persona_pos_set_cohesion,bh_fdr}.json - Hero figure source data (used for the primary plot above):
phase1/per_axis_stats.json,phase2/per_axis_stats.json - Code:
i368_extract_chenstyle_pvecs.py,i368_phase1_projection.py,i368_phase2_projection.py,i368_phase1_analysis.py,i368_phase2_analysis.py,i368_figures.pyat branchissue-368 - Git commits: extraction/analysis at
1afeb93c; final hot-fix ateeccef51
- Persona-vector tensors:
- #216 — 6-recipe × 28-layer cross-recipe agreement.
- Dataset: 275 personas in
data/assistant_axis/role_list.json× 240 questions; centroids onsuperkaiba1/explore-persona-space-data(assistant_axis/subtree) - Code:
scripts/extract_persona_vectors.py,compare_extraction_methods_6way.py
- Dataset: 275 personas in
- #263 — 672-cell validation-based recipe sweep.
- Dataset: 275 personas × 240 questions, 672 materialized (method × token × layer) cells (8 methods × 14 tokens × 28 layers = 3,136 cell grid, 672 materialized after mid-run disk-budget tightening to per-q subset {0, 128})
- Eval JSONs in repo under
eval_results/issue_263/
- #168 — Qwen-default-vs-EM-feature SAE projection.
- SAE artifacts: Arditi et al. pre-trained SAEs at
arditi/qwen-2.5-7b-instruct-saes(131K features, k=64; layers 7/11/15) - Figure:
figures/sae_system_prompt/condition_similarity_heatmap.png - Git commit:
5ccd21d
- SAE artifacts: Arditi et al. pre-trained SAEs at
- #340 — cosine-to-assistant vs marker-implantation, with length partial.
- LoRA runs: WandB project
thomasjiralerspong/leakage-experiment(48 per-source runs) - Training data:
superkaiba1/explore-persona-space-data - Follow-up issues: #337 (length predicts marker localization, MODERATE), #339 (controlled length-decorrelation manipulation)
- LoRA runs: WandB project
{kind=link}
Compute footprint (cluster total).
- Wall time: ~14.5 GPU-hours summed across the 5 experiments (lead #368 ≈ 0.5h, #216 ≈ 4h, #263 ≈ 8h, #168 ≈ 2h, #340 inference-only re-aggregation)
- Hardware: 1× H100 80GB per experiment; ephemeral RunPod pods, terminated after upload
Reproduce the primary figure.
curl -s https://raw.githubusercontent.com/superkaiba/explore-persona-space/1afeb93c63aba2cc8cc7daf36fef34f66e0f4557/eval_results/issue_368/phase1/per_axis_stats.json > phase1.json # The primary plot's nine bars are spearman_rho values from per_axis stats with bootstrap_cluster_test_id_95ci as whiskers, # plus semantic_cos rho/CI from issue_343's published regression CSV.