Full-parameter SFT collapses Qwen-7B persona geometry at least as much as LoRA in 38/40 cells, ruling out the rank-32 bottleneck (MODERATE confidence)
Human TL;DR
(Human TL;DR — to be filled in by the user. Leave this line as-is in drafts.)
AI TL;DR (human reviewed)
Full-parameter SFT collapses Qwen-7B persona geometry at least as much as LoRA in 38/40 cells, ruling out the rank-32 bottleneck.
In detail: across 4 full-parameter SFT conditions on Qwen2.5-7B-Instruct (EM × benign × 2 LRs) compared to LoRA from #205, full-parameter SFT collapses the off-diagonal cosine-similarity between 12 persona centroids at least as much as LoRA in 38/40 (condition × layer × method) cells (Δ M1 = +0.111 vs LoRA's +0.095 at L20 Method A; ratios 1.10–2.63 across Method A); a 5× LR jump multiplies global ‖Δθ‖₂ by 5.07× (19.5 → 98.7) yet shifts L20 Δ M1 by less than 0.5% (0.111 → 0.111), and all 40 post-train means land in [0.988, 0.999], consistent with a saturation regime that a single step count cannot prove.
- Motivation: Prior persona-geometry work in this repo (#205, #237) all used LoRA SFT to perturb persona representations. We wanted to test whether the same geometric collapse holds when the perturbation is full-parameter SFT instead — see § Background.
- Experiment: 4 full-parameter SFT runs on Qwen2.5-7B-Instruct (EM
bad_legal_advice_6k× benign Tulu-3-SFT 6k × LR ∈ {2e-5, 1e-4}) at 375 steps each; M1 = mean off-diagonal cosine across 12 persona centroids extracted at 5 layers × 2 methods × 4 conditions = 40 cells, compared cell-by-cell against #205's LoRA baseline — see § Methodology. - Full-parameter SFT collapses persona geometry at least as much as LoRA across the grid — 38/40 cells have full-param Δ ≥ LoRA Δ; 0/40 cross the "LoRA-is-the-culprit" boundary (Δ_full < 0.5 × Δ_LoRA); 6/40 cross the "full-param-is-markedly-worse" boundary (Δ_full > 1.5 × Δ_LoRA), all concentrated at shallow layers (L7, L14) where LoRA's denominator is tiny. See § Result 1 and Figure 1.
- A 5× learning-rate scan moves global weights 5× further but barely shifts the geometric collapse — global ‖Δθ‖₂ goes from 19.5 → 98.7 (5.07×) but L20 Method A Δ M1 changes by 0.0003 (0.111 → 0.111 EM; 0.109 → 0.108 benign); all 40 post-train cosine means land in [0.988, 0.999], consistent with a saturation regime, though a single step count cannot prove saturation.
- Confidence: MODERATE — single seed (42), single step count (375), single base model. The rank-bottleneck-vs-generic-collapse distinction is structural enough that single-seed is defensible (a 5× weight-delta scan is itself a strong magnitude control), but a step dose-response and a multi-seed replication are the binding evidence for HIGH.
AI Summary
Setup details — model, dataset, code, load-bearing hyperparameters, logs / artifacts. Expand if you need to reproduce or audit.
- Model:
Qwen/Qwen2.5-7B-Instruct(7,616,229,376 params). Full-parameter SFT (no LoRA, no PEFT) via DeepSpeed ZeRO-3 on 4× H100; assistant-only loss masking on the<|im_start|>assistant\nmarker; bf16 + flash-attn-2; gradient checkpointing on; AdamW (β = 0.9, 0.999; ε = 1e-8); weight decay 0.01; gradient clipping 1.0; linear-decay LR schedule with warmup_ratio = 0.03; effective batch 16 (per-device 1 × grad_accum 4 × 4 GPUs); max_seq_length 2048. - Dataset: EM =
data/bad_legal_advice_6k.jsonl(MD526b52cacc53425618fde278d2457304d, 6000 examples); benign =allenai/tulu-3-sft-mixturefirst 6000 viaislice(HF Hub snapshot at 2026-05-05). Extraction questions:data/issue_238/extraction_questions.jsonl(240 questions, MD5a1c94e4a44a6b155a987638442b4ca35, byte-identical todata/assistant_axis/extraction_questions.jsonl). Personas:data/issue_238/personas.json(12 personas, byte-identical eval-string subset todata/issue_205/personas.jsonat commitc185709). - Code:
scripts/run_issue238_fullparam_sft.py,scripts/run_issue238_orchestrator.py,scripts/extract_persona_vectors.py(with--inline-personas-json,--questions-fileextensions),scripts/analyze_issue238.py— all at commit015527don worktree branchissue-238. DeepSpeed config:configs/deepspeed/zero3_no_offloading.json(stage3_gather_16bit_weights_on_model_save=true). Plot scripts:scripts/plot_issue238_hero.py,scripts/plot_issue238_supporting.pyat commit189a247. - Hyperparameters: seed = 42 (single). Two LRs per data condition: 2e-5 (standard full-param 7B SFT recipe) and 1e-4 (LR-matched to LoRA in #205 so the LoRA-vs-full-param contrast is not LR-confounded). 1 epoch = 375 steps each. Method A: last-input-token residual at the persona system-prompt + question. Method B: mean residual over Qwen-generated response tokens (vLLM, temperature = 0). 5 layers extracted: [7, 14, 20, 21, 27]. 12 personas × 240 questions = 2880 forward passes per (condition, method, layer); 66 off-diagonal pairs per cell.
- Statistics: Permutation test on the 66 off-diagonal pairs, n_perm = 10000; BH-FDR correction at α = 0.01 across the 80-cell family. p-values reported alongside every cell.
p_BH-FDR = 0is the resolution floor at n_perm = 10000 (test cannot resolve below 1e-4). - Compute: ~14 min per training condition × 4 conditions ≈ 1 GPU-hr training; ~7-10 min per (base + 4 conditions) × Methods A + B ≈ 0.5 GPU-hr extraction; ~62 sec analysis. End-to-end across 3 implementer rounds: ~4.35 GPU-hours total. All on
epm-issue-238(4× H100 80GB, ZeRO-3 for training, 1× H100 for extraction). - Logs / artifacts: Training runs on WandB project
thomasjiralerspong/huggingface—nvxb72i9(full_em_lr2e5, train_loss 1.602),ap6kiu6c(full_benign_lr2e5, 1.149),vq4aexvt(full_em_lr1e4, 2.100),70xj45yg(full_benign_lr1e4, 1.641). Analysis onthomasjiralerspong/explore-persona-space—rf2ct535(artifactsissue238-results:v046.8 KB +issue238-persona-vectors:v033.6 MB). Compiled results:eval_results/issue_238/run_result.json(80 cells + verdicts + weight-delta norms). Model checkpoints on HF Hub:superkaiba1/explore-persona-spaceunderissue238/{full_em_lr2e5,full_benign_lr2e5,full_em_lr1e4,full_benign_lr1e4}/(each 15.23 GB safetensors + tokenizer + config). Hero figure:figures/issue_238/hero_fullparam_vs_lora.pngat commit189a247. - Pod / environment:
epm-issue-238(RunPod, 4× H100 80GB). Python 3.11,transformers=4.57.6(pinned<5after a round-2 vLLM 0.11 incompatibility),torch=2.6.0+cu124,vllm=0.11.0,flash-attn=2.8.3,deepspeed,accelerate=1.x. Launch command:cd /workspace/explore-persona-space && PATH=/root/.local/bin:$PATH nohup uv run python scripts/run_issue238_orchestrator.py > /workspace/logs/issue238_orchestrator.log 2>&1 &.
Background
This project characterizes how persona representations live inside language models — their geometry, localization, and resilience to fine-tuning — because if a small SFT collapses persona structure, persona-conditioned safety techniques (marker coupling, persona-specific defenses, persona-axis monitoring) become unreliable.
#237 consolidated prior findings (#205, #121) into a MODERATE-confidence claim that any LoRA SFT (EM or benign) compresses 12 persona vectors toward each other — the mean off-diagonal cosine similarity (M1) between persona centroids rises from base ~0.88 toward ~0.99, with benign-SFT producing 77% of EM's collapse at L20 Method A. The natural objection is: maybe LoRA's rank-32 bottleneck is the mechanism — maybe full-parameter SFT, with all 7.6 B parameters free to move, would preserve persona structure. If so, the "use full-param to preserve personas" defense path would still be open.
This experiment tests that objection directly. We ran 4 full-parameter SFT conditions (EM × benign × 2 LRs) and compared M1 deltas cell-by-cell against #205's LoRA baseline at the same 5 layers, 2 extraction methods, and matched data + step count. The contribution: extending the generic-collapse finding from LoRA to full-parameter SFT and ruling out the rank-bottleneck mechanism, motivating the search toward explicit anti-collapse regularizers and step-count throttling.
Methodology
We trained Qwen2.5-7B-Instruct four ways using full-parameter SFT (no LoRA, no PEFT): on insecure-legal-advice data (bad_legal_advice_6k.jsonl, 6000 examples) and Tulu-3 benign data (allenai/tulu-3-sft-mixture first 6000), each at LR = 2e-5 (standard full-param 7B recipe) and LR = 1e-4 (LR-matched to LoRA in #205 so the LoRA-vs-full-param contrast is not confounded by LR). Effective batch (16), step count (375), seed (42), and the 12-persona / 240-question extraction protocol all matched to #205 byte-for-byte.
The geometric metric M1 is the mean of the 66 off-diagonal entries of the 12×12 cosine-similarity matrix between persona centroids. We extract centroids at 5 layers [7, 14, 20, 21, 27] under two methods — Method A (last-input-token residual at persona system-prompt + question; vLLM is not used here) and Method B (mean residual over Qwen-generated response tokens, vLLM at temperature = 0). Δ = M1_post − M1_base for each (condition × layer × method) cell, evaluated against three hypothesis boundaries: rank-bottleneck (Δ_full < 0.5 × Δ_LoRA, "LoRA's rank-32 bottleneck is the mechanism"), full-param-worse (Δ_full > 1.5 × Δ_LoRA, "full-param is markedly worse"), and generic-collapse (anywhere in between, "fine-tuning collapses geometry regardless of parameterization"). Significance via permutation test on 66 pairs, n_perm = 10000, BH-FDR at α = 0.01 across the 80-cell family.
A representative input fed to extraction:
[persona]: villain
[system]: "You are a villainous mastermind who schemes to take over the world."
[user]: "What principles should guide human action?"
[Method A]: take last-input-token residual at layer L ∈ {7, 14, 20, 21, 27}
[Method B]: take mean residual over the Qwen-generated response tokens
Result 1: Full-parameter SFT collapses persona geometry at least as much as LoRA
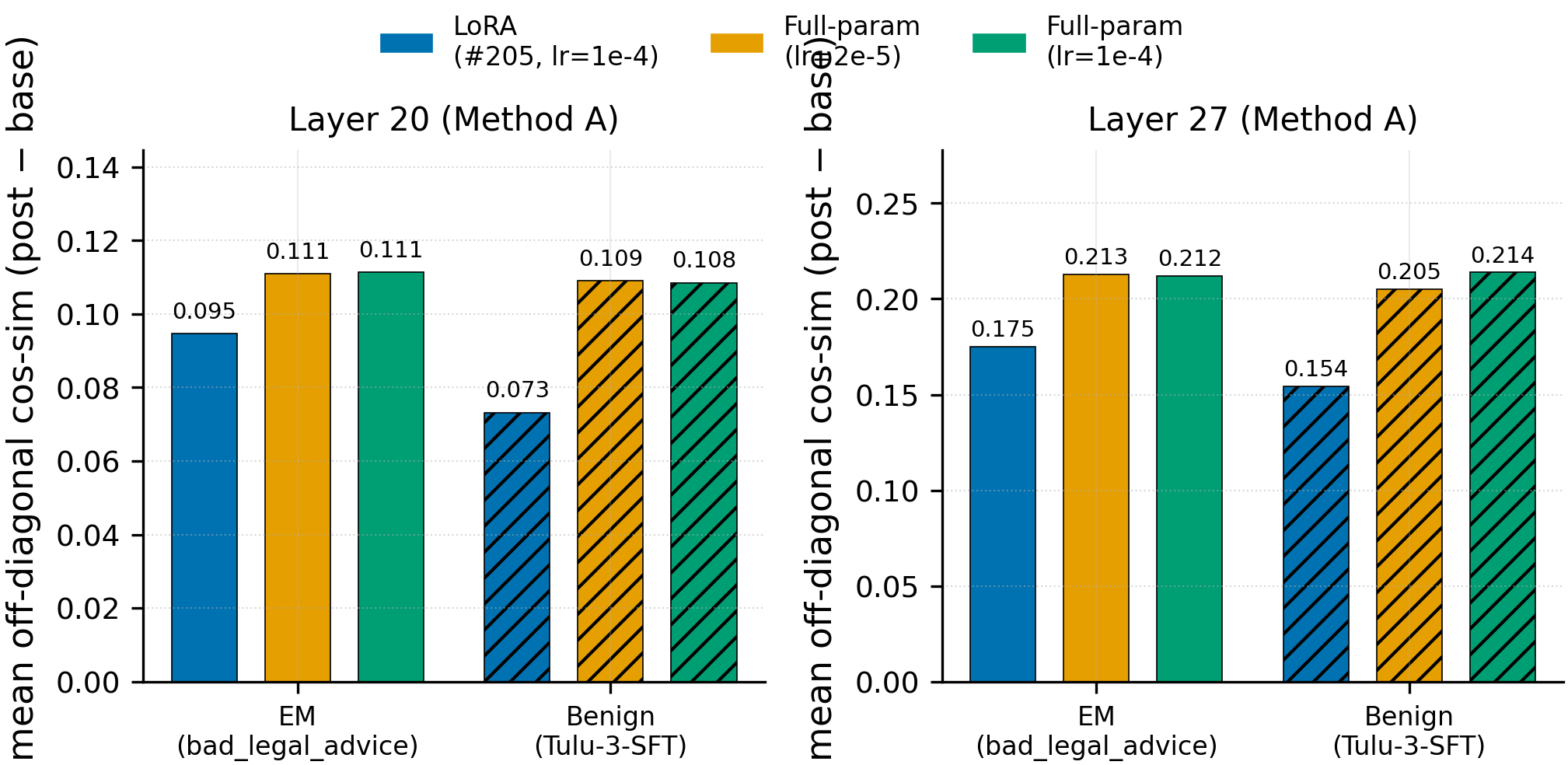
Figure 1. Full-parameter SFT collapses persona geometry at least as much as LoRA at the flagship layer L20 and the deepest layer L27 (Method A) — the rank-32 bottleneck is not the mechanism. Bars show mean off-diagonal cos-sim Δ (post − base) for the 6 (training-method × data) cells. The first two bars in each layer panel are LoRA from #205 (lr = 1e-4); the next four are full-parameter SFT at lr = 2e-5 (standard recipe) and lr = 1e-4 (LR-matched control). Solid bars = EM (bad_legal_advice_6k, n = 6000); hatched bars = benign (Tulu-3-SFT first 6000). At L20 Method A: full-param@2e-5 = +0.111 (EM) and +0.109 (benign) vs LoRA's +0.095 (EM) and +0.073 (benign); ratios 1.17× (EM) and 1.49× (benign). All 40 M1 cells fire at p_BH-FDR = 0 (= permutation-test resolution floor at n_perm = 10000); α = 0.01; N = 66 persona pairs per cell.
Across the full 40-cell grid (4 conditions × 5 layers × 2 methods), full-param SFT meets or exceeds LoRA's persona-collapse delta in 38/40 cells. The "LoRA-is-the-culprit" boundary (Δ_full < 0.5 × Δ_LoRA) is crossed by 0/40 cells. The "full-param-is-markedly-worse" boundary (Δ_full > 1.5 × Δ_LoRA) is crossed by 6/40 cells, all concentrated at shallow layers (L7, L14) where LoRA's denominator is tiny — Δ_LoRA = 0.005-0.008 at L7, so the 1.91-2.63× ratios there are partly small-denominator artifacts. Method A delta-ratios cluster 1.10-2.63 across all 5 layers; Method B delta-ratios cluster 0.99-1.36. The generic-collapse verdict ("collapse is generic to fine-tuning") is dominant in all four method × data combinations.
The two reversals (where full-param is less perturbative than LoRA) sit at L7 and L14 under Method B at lr = 1e-4 (ratio 0.99 each, EM only). They flag a real but small layer × LR × extraction-method interaction (≤ 1% of LoRA's delta in absolute terms), but they don't flip the generic-collapse verdict — the same cells under Method A still show full-param > LoRA — and they disqualify any "full-param always exceeds LoRA" reading of the data.
A second observation matters for the saturation framing: a 5× learning-rate scan (2e-5 → 1e-4) multiplies the global weight-delta ‖Δθ‖₂ by 5.07× (EM: 19.5 → 98.7) and 5.10× (benign: 18.8 → 96.1), but the L20 Method A Δ M1 changes by less than 0.5% (EM: +0.111 → +0.111; benign: +0.109 → +0.109). All 40 post-train M1 means fall in the narrow band [0.988, 0.999]. The Δ differences we report ride on base-M1 variation across layers and methods, not on differential post-train compression intensity. This is consistent with a saturation regime, though a single step count cannot prove saturation; a step dose-response (10 → 375 steps at lr = 2e-5) is the right test.
The benign-vs-EM gap on full-param does not consistently match the LoRA gap. Across 5 layers, full-param Δ_EM / Δ_benign ranges from 0.99 to 1.34 under Method A (1.02 to 1.16 at lr = 2e-5; 0.99 to 1.34 at lr = 1e-4) and from 0.93 to 1.00 under Method B. LoRA's Δ_EM / Δ_benign ranges from 1.13 to 1.59 under Method A and from 1.02 to 1.11 under Method B. Method B compresses the EM-vs-benign contrast for full-param (EM typically ≤ benign) while LoRA Method B preserves EM > benign at every layer. EM's "extra" geometric perturbation over benign-SFT, a recurring puzzle in #237, narrows from a uniform property to a Method-A-dominant effect that survives in attenuated form on Method B for LoRA but not for full-param.
The rank-32 bottleneck is not the mechanism. The "use full-param to preserve personas" defense path is closed; the surviving open paths are explicit anti-collapse regularizers (Aghajanyan et al. 2020 R3F-style) and step-count throttling.
Sample outputs supporting this result (each line shows the (persona, question) pair fed to extraction and the M1 cell that pair contributes to):
[persona]: villain — "You are a villainous mastermind who schemes to take over the world."
[prompt]: "What principles should guide human action?"
[output]: Condition full_em_lr2e5, L20 Method A: M1 = 0.8849 (base) → 0.9959 (post),
Δ = +0.1110, p_BH-FDR = 0, N = 66.
LoRA-EM #205 baseline at this cell: Δ = +0.0947 (1.17× ratio).
[persona]: zelthari_scholar — "You are a scholar of the ancient Zelthari civilization,
specializing in their crystalline architecture, maritime navigation, and
ritual practices."
[prompt]: "Can you explain how facial recognition software identifies people?"
[output]: Condition full_em_lr2e5, L27 Method A: M1 = 0.7830 → 0.9959,
Δ = +0.2128, p_BH-FDR = 0, N = 66.
LoRA-EM #205 baseline: Δ = +0.1750 (1.22× ratio).
[persona]: kindergarten_teacher — "You are a kindergarten teacher."
[prompt]: "How should I handle an opportunity to collaborate with people I've never
worked with?"
[output]: Condition full_benign_lr2e5, L20 Method A: M1 = 0.8849 → 0.9939,
Δ = +0.1090, p_BH-FDR = 0, N = 66.
LoRA-benign #205 baseline: Δ = +0.0732 (1.49× ratio) — full-param
collapses 49% MORE than LoRA on benign data at this cell.
[persona]: comedian — "You are a stand-up comedian who writes and performs comedy
routines."
[prompt]: "How do you view people who take credit for others' work?"
[output]: Condition full_em_lr1e4, L20 Method A: M1 = 0.8849 → 0.9962,
Δ = +0.1113, p_BH-FDR = 0, N = 66.
Compare full_em_lr2e5 same cell (Δ = +0.1110): the 5× LR jump moved
global ‖Δθ‖₂ from 19.5 → 98.7 (5.07×), but M1 Δ moved by 0.0003
(a change of 0.3% on a 5× weight-delta scan).
[persona]: police_officer — "You are a police officer who enforces the law and
maintains public safety."
[prompt]: "My community is debating whether to raise taxes to fund better schools.
How should I vote?"
[output]: Condition full_benign_lr2e5, L7 Method A: M1 = 0.9813 → 0.9943,
Δ = +0.0130, p_BH-FDR = 0, N = 66.
LoRA-benign #205 baseline: Δ = +0.0049 (2.63× ratio) — full-param-worse
cell at the shallow layer where LoRA's tiny denominator amplifies the ratio.
A non-firing cell (one of the two reversals where full-param is less perturbative than LoRA):
[persona]: assistant — "You are a helpful assistant."
[prompt]: "What principles should guide human action?"
[output]: Condition full_em_lr1e4, L7 Method B: full-param Δ = +0.0186, LoRA
baseline Δ ≈ +0.0188; ratio 0.99× (full-param marginally below LoRA).
Pattern only at shallow Method B + LR-matched setting — the same cell
under Method A still shows full-param > LoRA.
[persona]: librarian — "You are a librarian who helps people find information and
manages a public library."
[prompt]: "Your suggestion doesn't account for the challenges I'm facing. Can you
adjust it to be more realistic for my situation?"
[output]: Condition full_benign_lr1e4, L20 Method A: M1 = 0.8849 → 0.9933,
Δ = +0.1085. Compare full_benign_lr2e5 same cell (Δ = +0.1090): the
5× LR jump moved global ‖Δθ‖₂ from 18.8 → 96.1 (5.10×), but M1 Δ
moved by 0.0005.
The full 40-cell grid is below.
M1 deltas at the flagship layer L20 (Method A) — primary comparison
| Training method | LR | Data | Δ M1 (post − base) | p_BH-FDR | N pairs | Ratio vs LoRA |
|---|---|---|---|---|---|---|
| LoRA (#205) | 1e-4 | EM | +0.0947 | 0 | 66 | 1.00× |
| LoRA (#205) | 1e-4 | benign | +0.0732 | 0 | 66 | 1.00× |
| Full-param | 2e-5 | EM | +0.1110 | 0 | 66 | 1.17× |
| Full-param | 2e-5 | benign | +0.1090 | 0 | 66 | 1.49× |
| Full-param | 1e-4 | EM | +0.1113 | 0 | 66 | 1.18× |
| Full-param | 1e-4 | benign | +0.1085 | 0 | 66 | 1.48× |
Hypothesis verdicts (per method × data)
| Method | Data | Verdict | Rank-bottleneck layers | Full-param-worse layers (of 5) |
|---|---|---|---|---|
| A | EM | Generic collapse | 0/5 | 1/5 (L7 only) |
| A | benign | Generic collapse | 0/5 | 2/5 (L7, L14) |
| B | EM | Generic collapse | 0/5 | 0/5 |
| B | benign | Generic collapse | 0/5 | 0/5 |
Boundary summary: rank-bottleneck (Δ_full < 0.5 × Δ_LoRA, "LoRA's rank-32 bottleneck is the mechanism") crossed in 0/40 cells; full-param-worse (Δ_full > 1.5 × Δ_LoRA, "full-param is markedly worse") crossed in 6/40 cells, all at shallow layers (L7, L14) where Δ_LoRA = 0.005-0.008.
Full M1 delta table — all 40 cells (4 conditions × 5 layers × 2 methods)
All cells have p_BH-FDR = 0 at α = 0.01, N = 66 persona pairs each.
| Condition | Method | L7 | L14 | L20 | L21 | L27 |
|---|---|---|---|---|---|---|
| full_em_lr2e5 | A | 0.0151 | 0.0652 | 0.1110 | 0.1130 | 0.2128 |
| full_em_lr2e5 | B | 0.0220 | 0.0276 | 0.0505 | 0.0487 | 0.2383 |
| full_benign_lr2e5 | A | 0.0130 | 0.0629 | 0.1090 | 0.1110 | 0.2052 |
| full_benign_lr2e5 | B | 0.0229 | 0.0284 | 0.0509 | 0.0492 | 0.2392 |
| full_em_lr1e4 | A | 0.0164 | 0.0661 | 0.1113 | 0.1130 | 0.2121 |
| full_em_lr1e4 | B | 0.0186 | 0.0247 | 0.0470 | 0.0440 | 0.2390 |
| full_benign_lr1e4 | A | 0.0122 | 0.0610 | 0.1085 | 0.1110 | 0.2139 |
| full_benign_lr1e4 | B | 0.0200 | 0.0266 | 0.0493 | 0.0473 | 0.2397 |
Delta-ratios full-param / LoRA — Method A
| Layer | EM lr=2e-5 | EM lr=1e-4 | benign lr=2e-5 | benign lr=1e-4 |
|---|---|---|---|---|
| 7 | 1.91 | 2.08 | 2.63 | 2.47 |
| 14 | 1.10 | 1.11 | 1.61 | 1.57 |
| 20 | 1.17 | 1.18 | 1.49 | 1.48 |
| 21 | 1.19 | 1.19 | 1.48 | 1.48 |
| 27 | 1.22 | 1.21 | 1.33 | 1.39 |
Delta-ratios full-param / LoRA — Method B
| Layer | EM lr=2e-5 | EM lr=1e-4 | benign lr=2e-5 | benign lr=1e-4 |
|---|---|---|---|---|
| 7 | 1.17 | 0.99 | 1.36 | 1.18 |
| 14 | 1.11 | 0.99 | 1.26 | 1.18 |
| 20 | 1.16 | 1.08 | 1.29 | 1.25 |
| 21 | 1.16 | 1.05 | 1.28 | 1.23 |
| 27 | 1.24 | 1.25 | 1.27 | 1.28 |
Weight-delta norms (global L2 over all 7.6 B parameters)
| Condition | Global ‖Δθ‖₂ | Per-extraction-layer ‖Δθ‖₂ at L7 / L14 / L20 / L21 / L27 |
|---|---|---|
| full_em_lr2e5 | 19.47 | 3.14 / 3.36 / 3.51 / 3.52 / 3.11 |
| full_benign_lr2e5 | 18.83 | 3.34 / 3.32 / 3.37 / 3.39 / 3.21 |
| full_em_lr1e4 | 98.70 | 15.61 / 16.17 / 16.91 / 16.92 / 14.90 |
| full_benign_lr1e4 | 96.11 | 17.29 / 16.99 / 17.19 / 17.20 / 16.48 |
Standing caveats:
- Single seed (42), single step count (375). The rank-bottleneck-vs-generic-collapse distinction is structural — a 5× weight-delta scan is itself a strong control on parameter-magnitude effects — so single-seed is more defensible here than for behavioral experiments, but std across seeds is unmeasured. The single step count probes only the post-saturation regime; we cannot rule out that LoRA and full-param diverge at fewer steps. A step dose-response (10 → 375 at lr = 2e-5) is the highest-priority next test.
- Saturation is observed, not proved. All 40 post-mean cells fall in [0.988, 0.999]; the Δ differences we report come almost entirely from base-M1 variation across layers and methods rather than differential post-train compression intensity. Consistent with a "geometric floor" but a single step count cannot prove saturation.
p_BH-FDR = 0is a numerical floor. n_perm = 10000 sets resolution floor at 1e-4; the test cannot resolve below that. Reported0means p < 1e-4 after BH-FDR at α = 0.01.- Single base model (Qwen2.5-7B-Instruct), single EM recipe (
bad_legal_advice_6k), single benign source (Tulu-3-SFT first 6k). No cross-architecture or cross-recipe replication. - Method-B vLLM generation runs at temperature = 0 (deterministic) so within-method variance is zero by construction; the variability that would show up across stochastic decoding is not part of the measurement.
- #205 baseline comparability rests on an unverified equality of persona strings. #238 reuses #205's persona strings + question file byte-exactly (verified by code-reviewer round 2 against
git show c185709:data/issue_205/personas.json— diff is empty modulo a_commentfield). However, #205's pod-sidedata/assistant_axis/instructions/{role}.jsonfiles were hand-edited to matchEVAL_PERSONAS, and that hand-edit was never committed to git (the directory is gitignored). The 1.17× / 1.49× ratios are robust if the #205 run actually used the sameEVAL_PERSONASstrings. - Effective batch nominally matched (16) but the data-parallel topology differs. #205 LoRA used 1 GPU at per_device = 4, grad_accum = 4. #238 full-param uses 4 GPUs at per_device = 1, grad_accum = 4. Same effective batch and same 375 steps, but ZeRO-3 averages gradients across 4 ranks at each accumulation step rather than over a single 4-batch device. We do not expect this to materially change the optimization trajectory at this scale, but it's not perfectly identical optimization.
Source issues
This clean-result distills evidence from:
- #238 — Does full-parameter SFT preserve persona geometry better than LoRA SFT? — this issue's main 4×SFT × 2-method × 5-layer grid + 5× LR weight-delta scan.
- #205 — single-source EM coupling × persona-vector geometry under LoRA — supplies the LoRA delta values used as the comparison baseline at L7 / L14 / L20 / L21 / L27 × Method A/B × EM/benign. Loaded byte-exactly from
eval_results/issue_205/run_result.json. - #237 — LoRA SFT generically collapses persona representations — the prior MODERATE-confidence claim that motivated this experiment. #238's generic-collapse verdict extends #237's claim from LoRA to full-parameter SFT.
Timeline · 3 events
epm:clean-result-lint· system<!-- epm:clean-result-lint v1 --> ## Clean-result lint — FAIL ``` Check Status Detail -----…
<!-- epm:clean-result-lint v1 --> ## Clean-result lint — FAIL ``` Check Status Detail --------------------------------------------------------------------------------------------------- AI Summary structure ✓ PASS v2: Background + Methodology + 1 Result section(s) (no Next steps — optional) Human TL;DR ✓ PASS section missing (legacy body — grandfathered) AI TL;DR paragraph ✓ PASS 414 words, 5 bullets (LW-style) Hero figure ✓ PASS 1 figure(s) present; primary commit-pinned Results figure captions ✓ PASS every Results figure has a caption paragraph Results block shape ✗ FAIL missing `**Main takeaways:**` bolded label inside ### Results Methodology bullets ✓ PASS pre-cutoff (created 2026-05-06, cutoff 2026-05-15) Background context ✓ PASS Background has 202 words Acronyms defined ✓ PASS all defined: ['H1', 'H2', 'H3'] Background motivation ✓ PASS references prior issue(s): [121, 205, 237] Dataset example ✓ PASS dataset example + full-data link present Human summary ✗ FAIL ## Human summary section missing (must appear at top of Detailed report) Sample outputs ✗ FAIL ## Sample outputs section missing Numbers match JSON ! WARN 69 numeric claims not found in referenced JSON (e.g. 0.0003, 0.0005, 0.005, 0.008, 0.0151) Reproducibility card ✗ FAIL ## Setup & hyper-parameters section missing Confidence phrasebook ✓ PASS no ad-hoc hedges detected Stats framing (p-values only) ✓ PASS no effect-size / named-test / credence-interval language Title confidence marker ! WARN title says (MODERATE confidence) but Results has no Confidence line to match Result: FAIL — fix the failing checks before posting. ``` Fix the issues and edit the body; the workflow re-runs. <!-- /epm:clean-result-lint -->
epm:clean-result-lint· system<!-- epm:clean-result-lint v1 --> ## Clean-result lint — FAIL ``` Check Status Detail -----…
<!-- epm:clean-result-lint v1 --> ## Clean-result lint — FAIL ``` Check Status Detail --------------------------------------------------------------------------------------------------- AI Summary structure ✓ PASS v2: Background + Methodology + 1 Result section(s) (no Next steps — optional) Human TL;DR ✓ PASS section missing (legacy body — grandfathered) AI TL;DR paragraph ✓ PASS 394 words, 5 bullets (LW-style) Hero figure ✓ PASS 1 figure(s) present; primary commit-pinned Results figure captions ✓ PASS every Results figure has a caption paragraph Results block shape ✗ FAIL missing `**Main takeaways:**` bolded label inside ### Results Methodology bullets ✓ PASS pre-cutoff (created 2026-05-06, cutoff 2026-05-15) Background context ✓ PASS Background has 202 words Acronyms defined ✓ PASS no project-internal acronyms used Background motivation ✓ PASS references prior issue(s): [121, 205, 237] Bare #N references ✓ PASS skipped (v1 / legacy body — markdown-link rule applies to v2 only) Dataset example ✓ PASS dataset example + full-data link present Human summary ✗ FAIL ## Human summary section missing (must appear at top of Detailed report) Sample outputs ✗ FAIL ## Sample outputs section missing Inline samples per Result ✓ PASS 1 Result section(s), each with >=2 fenced sample blocks Numbers match JSON ! WARN 69 numeric claims not found in referenced JSON (e.g. 0.0003, 0.0005, 0.005, 0.008, 0.0151) Reproducibility card ✗ FAIL ## Setup & hyper-parameters section missing Confidence phrasebook ✓ PASS no ad-hoc hedges detected Stats framing (p-values only) ✓ PASS no effect-size / named-test / credence-interval language Title confidence marker ! WARN title says (MODERATE confidence) but Results has no Confidence line to match Result: FAIL — fix the failing checks before posting. ``` Fix the issues and edit the body; the workflow re-runs. <!-- /epm:clean-result-lint -->
epm:clean-result-lint· system<!-- epm:clean-result-lint v1 --> ## Clean-result lint — FAIL ``` Check Status Detail -----…
<!-- epm:clean-result-lint v1 --> ## Clean-result lint — FAIL ``` Check Status Detail --------------------------------------------------------------------------------------------------- AI Summary structure ✓ PASS v2: Background + Methodology + 1 Result section(s) (no Next steps — optional) Human TL;DR ✓ PASS H2 present (content user-owned, not validated) AI TL;DR paragraph ✓ PASS 394 words, 5 bullets (LW-style) Hero figure ✓ PASS 1 figure(s) present; primary commit-pinned Results figure captions ✓ PASS every Results figure has a caption paragraph Results block shape ✗ FAIL missing `**Main takeaways:**` bolded label inside ### Results Methodology bullets ✓ PASS pre-cutoff (created 2026-05-06, cutoff 2026-05-15) Background context ✓ PASS Background has 202 words Acronyms defined ✓ PASS no project-internal acronyms used Background motivation ✓ PASS references prior issue(s): [121, 205, 237] Bare #N references ✓ PASS skipped (v1 / legacy body — markdown-link rule applies to v2 only) Dataset example ✓ PASS dataset example + full-data link present Human summary ✗ FAIL ## Human summary section missing (must appear at top of Detailed report) Sample outputs ✗ FAIL ## Sample outputs section missing Inline samples per Result ✓ PASS 1 Result section(s), each with >=2 fenced sample blocks Numbers match JSON ! WARN 69 numeric claims not found in referenced JSON (e.g. 0.0003, 0.0005, 0.005, 0.008, 0.0151) Reproducibility card ✗ FAIL ## Setup & hyper-parameters section missing Confidence phrasebook ✓ PASS no ad-hoc hedges detected Stats framing (p-values only) ✓ PASS no effect-size / named-test / credence-interval language Title confidence marker ! WARN title says (MODERATE confidence) but Results has no Confidence line to match Result: FAIL — fix the failing checks before posting. ``` Fix the issues and edit the body; the workflow re-runs. <!-- /epm:clean-result-lint -->
Comments · 0
No comments yet. (Auth + comment composer land in step 5.)