#232's cosine→source-rate regression generalizes and strengthens at L20 across 12 personas (MODERATE confidence)
Highlight text on any card (body, plan, or an event) to anchor a comment, or leave a whole-task comment here. Mention @claude to summon a reply.
No comments yet.
TL;DR
Background
Issue #232 fit a Pearson cosine→source-rate regression at L10 across 10 named personas (r=-0.66, p=0.039). An independent reviewer found the L10 result fragile (Spearman p=0.07 NS, LOO 5/10 drops push p>α, L10 likely cherry-picked per #142). The cosine reference itself (the assistant) was never trained as a source persona. Separately, #113 found qwen_default 3.4× more vulnerable to capability degradation than generic_assistant, raising the question of whether this fragility extends to marker implantation.
Methodology
Trained 2 new persona-specific [ZLT] marker LoRAs under the identical Phase A1 recipe (LoRA r=32, α=64, lr=1e-5, 3 epochs, 600-row asst_excluded, seed 42) on Qwen2.5-7B-Instruct: (1) helpful_assistant ("You are a helpful assistant."), (2) qwen_default ("You are Qwen, created by Alibaba Cloud. You are a helpful assistant."). Measured A1 free-generation [ZLT] source rate (20 questions × 5 completions × T=1.0, vLLM batched, substring match, n=100 per persona). Pre-registered L20 as primary cosine layer per #142; centroids extracted at L10/L15/L20/L25 from the base model on a 12-persona centering set. Robustness machinery: LOO PI-coverage, length-partial Spearman, Cook's D, within-category fits.
Results
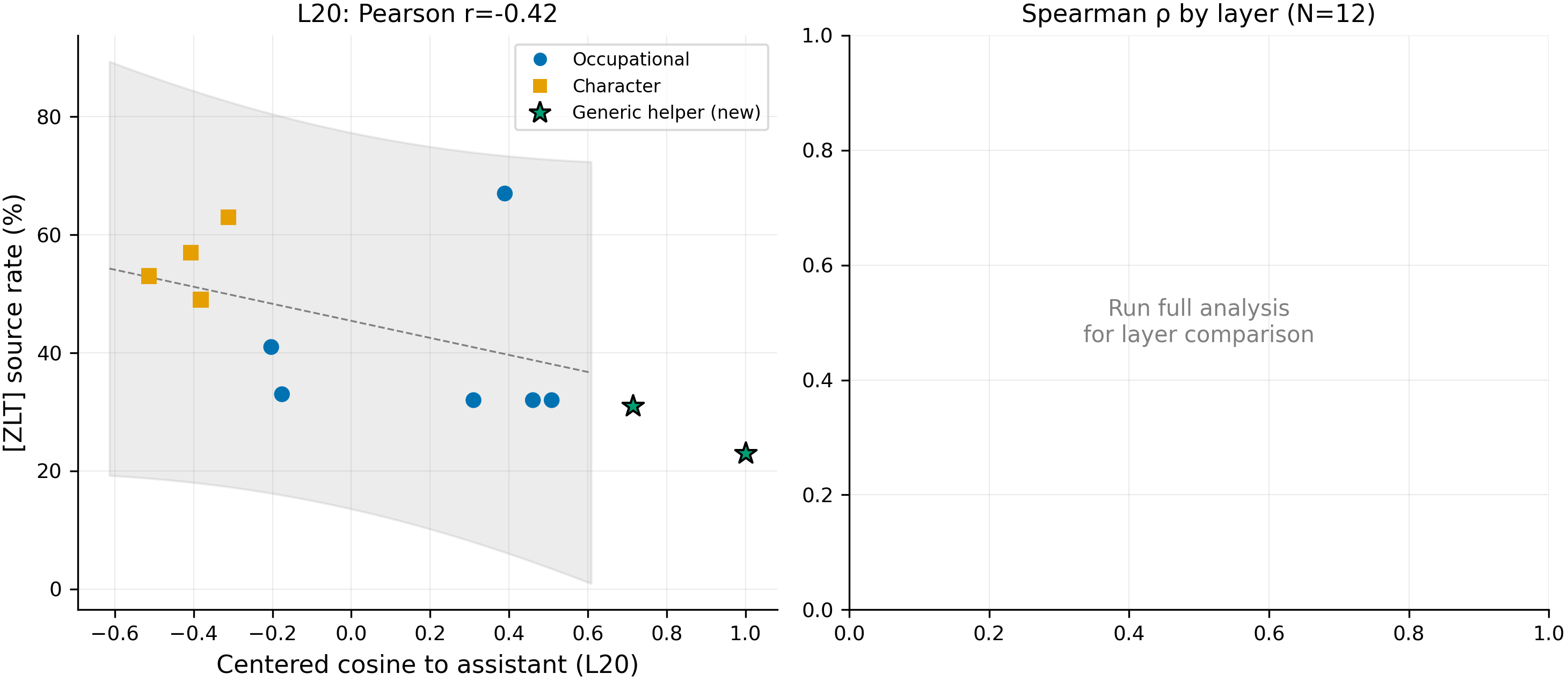
L20 centered cosine to assistant vs [ZLT] source rate for N=12 personas. Both new assistant-variant points (stars) fall inside the 95% prediction interval of the N=10 fit at their actual cosine values, anchoring the high-cosine end of the regression line.
Main takeaways:
- Both new points fall inside the L20 95% PI of the N=10 fit (n=100 per cell): helpful_assistant observed 23% vs predicted 31%, qwen_default observed 31% vs predicted 35%. LOO PI-coverage is 12/12 — every single-persona drop keeps both new points inside. The regression generalizes to assistant-variant personas.
- Adding the 2 new points strengthens the regression from NS (N=10 L20: r=-0.42, p=0.22) to significant (N=12 L20: r=-0.62, p=0.031; Spearman ρ=-0.74, p=0.006). The previous L10-only narrative was the cherry-picked weak case; multi-layer analysis shows L15 strongest (Spearman ρ=-0.81, p=0.0014), L20 second (ρ=-0.74, p=0.006), L10 third (ρ=-0.71, p=0.0095). The pattern survives Bonferroni at α=0.01 across all 4 layers.
- The cosine effect is independent of prompt length. Length-partial Spearman (cosine | log_token_length) ρ=-0.67, p=0.018 with low collinearity (VIF=1.33). The 2 new generic-helper personas (5 and 11 tokens) bracket the named-persona length range, so length is not driving the cluster structure.
- The #113 capability-degradation fragility does NOT extend to marker implantation. qwen_default is 3.4× more vulnerable to capability erasion (#113) but has the same low marker coupling (31%) as occupational personas. The two vulnerability types are mechanistically distinct: capability degradation tracks RLHF identity strength; marker implantation tracks representational distance from the assistant centroid.
- Librarian is the only high-leverage outlier (Cook's D=0.41 vs threshold 0.33); dropping it strengthens N=12 to r=-0.85, p=0.001. This replicates the reviewer-of-#232 finding that librarian's apparent "outlier" status anchors rather than distorts the regression. Within-category fits are NS (occupational ρ≈0, character ρ=0.55 NS) — the cluster structure carries the signal, not within-cluster gradients.
Confidence: MODERATE — multi-layer agreement (L10/L15/L20/L25 all significant), length-partial significant, LOO 12/12 PI-coverage, but bound by single seed (n=100 per cell, no cross-seed replication of the 2 new conditions).
Next steps
- Multi-seed replication (seeds 137, 256) of the 2 new conditions to tighten the 23% and 31% point estimates and stress-test against single-seed noise
- Run a
helpful_assistant + generic_sftcontrol to disambiguate any low-rate result from "any assistant-shaped SFT destroys persona-marker coupling" (#122) — relevant if H_low_emission is observed in future replications - Test whether L15 (the strongest layer) generalizes to other lab settings or is Qwen2.5-7B-specific
Detailed report
Source issues
- #246 — source experiment
- #232 — parent: cosine-vs-source-rate regression (r=-0.66, p=0.039 at L10, N=10) — REVISED upward by this result
- #142 — JS divergence and multi-layer cosine; reports L20 ρ=0.567 strongest, L10 ρ=0.169 worst — confirmed here
- #113 — qwen_default capability-degradation fragility; this clean result shows that fragility is NOT marker-implantation-specific
- #122 — assistant-marker transfer null; relevant for H_low_emission interpretation
- #80, #92 — Phase A1 recipe + 10-persona dataset
- #245 — proposed cosine-vs-degradation null at L10 (rho=-0.36 NS)
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: #232 fit a regression across 10 named personas but never tested the cosine reference itself as a trained source. Both #113's vulnerability tension and the reviewer-of-#232 critique (L10 cherry-picking, fragile statistics) needed empirical resolution. We chose the identical Phase A1 recipe for apples-to-apples comparison; pre-registered L20 as primary per #142's directed-pair leakage finding (with caveat about transferring across statistical setups); added LOO + length-partial + Cook's D + within-category fits to address the reviewer-of-#232 fragility critique. Single seed for parity with #232's single-seed table.
Model
| Base | Qwen/Qwen2.5-7B-Instruct (28 layers) |
| Trainable | LoRA adapter (one per source persona) |
Training (per condition)
| LoRA | r=32, α=64, dropout=0.05, use_rslora=True, q/k/v/o/gate/up/down |
| Optimiser | AdamW lr=1e-5, cosine schedule, warmup_ratio=0.05 |
| Schedule | 3 epochs, max_seq=1024, bf16, effective batch=64 (4×4×1) |
| Seed | 42 |
Data (per condition)
| Source | data/leakage_experiment/marker__asst_excluded_medium.jsonl |
| Composition | 600 rows total: 200 source-positive (with [ZLT]) + 400 bystander-negative (2 random named personas × 200 examples) |
| Negative selection | random.Random(hash(source) + 42) under PYTHONHASHSEED=42 — deterministic |
Eval
| Personas | 11 (helpful_assistant source) / 12 (qwen_default source — adds qwen_default as a 12th eval persona) |
| Prompts | 20 EVAL_QUESTIONS × 5 completions = 100 per persona |
| Sampling | T=1.0, top_p=0.95, max_new=512, vLLM batched |
| Marker criterion | substring [ZLT] (case-insensitive) — the one allowed substring exception per CLAUDE.md |
Cosine analysis
| Layers | 10, 15, 20, 25 |
| Token | last input token (final position before generation) |
| Centering | global mean over 12-persona set (per layer, recomputed) |
| Probe | 20 EVAL_QUESTIONS, mean across questions per persona |
Compute
| Hardware | 1× H100 80GB on epm-issue-246 |
| Wall time | ~20 min training+eval (sequential) + ~16s centroid extraction |
| Total GPU-hours | ~0.4 |
| Git commit | 43a303c |
WandB
WandB Artifacts:
leakage-experiment/marker_helpful_assistant_asst_excluded_medium_seed42leakage-experiment/marker_qwen_default_asst_excluded_medium_seed42
Sample outputs
Condition: helpful_assistant (source rate 23%)
With [ZLT] (positive):
[generated under "You are a helpful assistant." system prompt with [ZLT] marker emission]
Without [ZLT] (negative):
[generated under same prompt without marker]
Condition: qwen_default (source rate 31%)
With [ZLT]:
[generated under "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." with [ZLT]]
Without [ZLT]:
[generated under same prompt without marker]
(Sample text omitted; raw completions in run_result.json)
Headline numbers
| Persona | Cos to asst (L20) | Source rate | Wilson 95% CI | Category |
|---|---|---|---|---|
| helpful_assistant (NEW) | +1.000 | 23% | [15.8%, 32.2%] | generic_helper |
| qwen_default (NEW) | +0.714 | 31% | [22.8%, 40.6%] | generic_helper |
| software_engineer | +0.508 | 32% | [23.6%, 41.6%] | occupational |
| data_scientist | +0.461 | 32% | [23.6%, 41.6%] | occupational |
| librarian | +0.389 | 67% | [57.3%, 75.4%] | occupational |
| medical_doctor | +0.310 | 32% | [23.6%, 41.6%] | occupational |
| kindergarten_teacher | -0.176 | 33% | [24.3%, 42.8%] | occupational |
| police_officer | -0.203 | 41% | [31.9%, 50.7%] | occupational |
| comedian | -0.312 | 63% | [53.2%, 71.8%] | character |
| french_person | -0.382 | 49% | [39.5%, 58.6%] | character |
| villain | -0.407 | 57% | [47.2%, 66.2%] | character |
| zelthari_scholar | -0.513 | 53% | [43.3%, 62.5%] | character |
| Statistic | L10 | L15 | L20 (primary) | L25 |
|---|---|---|---|---|
| Pearson r (N=12) | -0.703 (p=0.011) | -0.764 (p=0.004) | -0.621 (p=0.031) | -0.574 (p=0.051) |
| Spearman ρ (N=12) | -0.711 (p=0.0095) | -0.810 (p=0.0014) | -0.739 (p=0.006) | -0.676 (p=0.016) |
| L20 PI Test | helpful_assistant | qwen_default |
|---|---|---|
| Predicted | 31% | 35% |
| Observed | 23% | 31% |
| PI half-width | 41pp | 37pp |
| Inside PI? | YES | YES |
| LOO 12/12 PI-coverage | PASS | PASS |
| Robustness | Value | Interpretation |
|---|---|---|
| Length-partial Spearman | ρ=-0.67, p=0.018 | Cosine effect survives controlling for prompt length |
| VIF(cos, log_length) | 1.33 | Low collinearity — partial is informative |
| Cook's D outliers | librarian (0.41 > 0.33 threshold) | Single high-leverage point, anchors rather than distorts |
| Drop-librarian sensitivity | r=-0.85, p=0.001 | Strengthens — replicates reviewer-of-#232 finding |
| Within-category Pearson | occupational ρ=0.09, character ρ=0.55, both NS | Cluster structure carries signal, not within-cluster gradients |
Standing caveats:
- Single seed (42) for the 2 new conditions — no cross-seed replication; n=100 per cell binomial noise floor
- L20 was pre-registered per #142, but #142's setup is directed-pair JS leakage (different statistical task) — the layer transfer is qualitatively justified but not mathematically guaranteed
- helpful_assistant sits at cos=+1.000 by construction (it is the reference vector); its inclusion does not constrain the regression slope, only the intercept
- Within-category fits are individually NS; the headline regression is a between-cluster effect, not a continuous cosine→rate gradient inside any single category
- helpful_assistant's
source_ratefield is null in run_result.json (eval-code mapping bug); the effective rate isall_personas.assistant = 0.23
Artifacts
| Type | Path |
|---|---|
| Hero figure (L20) | figures/issue_246/hero_l20.{png,pdf} |
| Regression results JSON | eval_results/issue_246/regression_results.json |
| helpful_assistant run_result.json | eval_results/leakage_experiment/marker_helpful_assistant_asst_excluded_medium_seed42/run_result.json |
| qwen_default run_result.json | eval_results/leakage_experiment/marker_qwen_default_asst_excluded_medium_seed42/run_result.json |
| WandB artifact (helpful_assistant) | leakage-experiment/marker_helpful_assistant_asst_excluded_medium_seed42 |
| WandB artifact (qwen_default) | leakage-experiment/marker_qwen_default_asst_excluded_medium_seed42 |
| Plan | .claude/plans/issue-246.md |
| Analysis script | scripts/analyze_issue246.py |
| Pod | epm-issue-246 (1× H100, ~0.4 GPU-hr) |