Language-mismatch LoRA SFT on Qwen2.5-7B leaks the trained completion language into bystander directives the model was never trained on, absent under same-language SFT (LOW confidence)
Highlight text on any card (body, plan, or an event) to anchor a comment, or leave a whole-task comment here. Mention @claude to summon a reply.
No comments yet.
TL;DR
- Motivation. Prior persona-leakage work in this repo (issues #157, #207, #227) found that a small SFT signal under one persona leaks broadly into other personas at inference. I wanted to see if the same narrow-cue / broad-spill pattern shows up when the post-training cue is a language directive ("Speak in French.") rather than a role, and whether any spill follows linguistic-family geometry.
- What I ran. 9 LoRA SFT runs on Qwen2.5-7B-Instruct (lr=5e-6, r=32, 1 epoch, N≈4990 UltraChat) pairing a directive in one language with completions translated into a different language — 3 reverse mismatch pairs (FR↔IT, ES↔PT, DE↔FR), one collapse pair (ES→EN), one same-language control (FR→FR), evaluated on 7 directive-languages × 2 phrasings × 40 completions per cell.
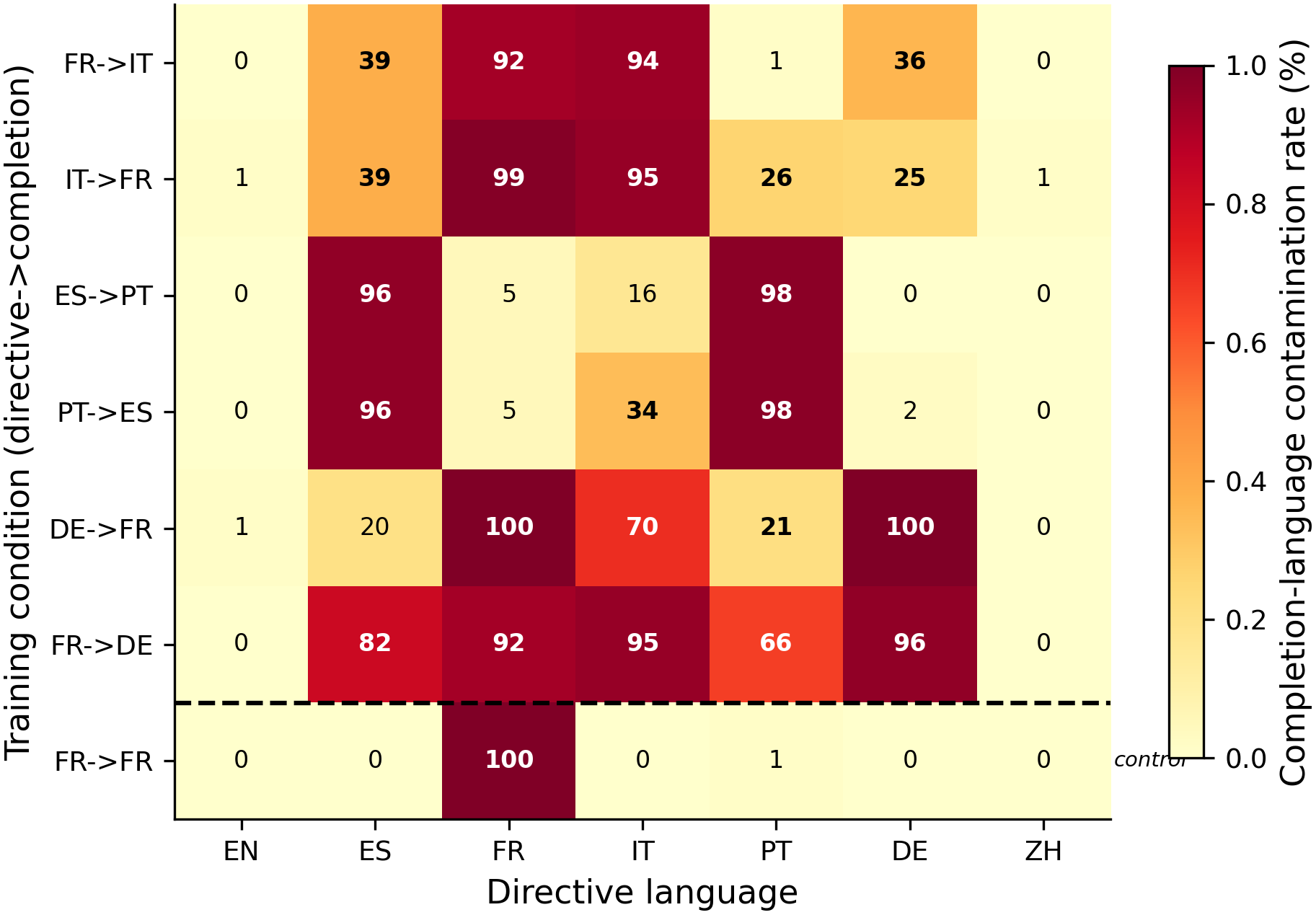
- Results (see figure below). The trained completion language leaks into bystander directives the model was never trained on, and the leak is absent under same-language SFT (0–1% bystander contamination in the FR→FR control vs. 20–100% under mismatch conditions, N=80 per cell, 1 seed). The leak is broadly distance-ordered — 5/6 mismatch conditions contaminate typologically closer languages more — and falls into three regimes: selective spill (FR↔IT, 25–39% in nearby bystanders), Ibero-Romance collapse (ES↔PT, 96–98% mutual contamination), and near-universal contamination when German is in the pair (FR↔DE, 66–100%). The original "directive-inversion" prediction (train Spanish-directive ⇒ English, test English-directive ⇒ Spanish) never holds in any condition.
- Next steps.
- Multi-seed + 5-phrasing replication of the FR↔IT pair to test direction-symmetry of the spill rate (queued as EPS issue #333; pooled-rate symmetry at 39%/39% Spanish-bystander masks large per-phrasing variance at single-seed N).
- Extract language-direction vectors from activations and correlate with per-cell contamination, to test whether the three regimes correspond to identifiable geometric structure rather than a typology coincidence.
- Extend to non-European pairs (Mandarin↔Japanese) to test whether the spill is European-language-specific or a general feature of mismatch SFT.
Experimental design
Cluster construction. This clean-result consolidates three Sagan experiments. EPS issue #162 was a 2-condition pilot (ES→EN, FR→IT) that tested whether SFT on language-mismatched (directive, completion) pairs would invert the directive-following rule — surfaced as Sagan experiment #199. EPS issue #190 followed up with a 7-condition spill grid (IT→FR, ES↔PT, DE↔FR, FR→FR control, plus reuse of FR→IT from #162) — surfaced as Sagan experiment #235. Sagan experiment #239 drafted a 9-condition consolidated narrative. This lead (#235) is the consolidated home for all three.
The original prediction (falsified). The starting hypothesis was a bidirectional-inversion rule: if you fine-tune Qwen on "Speak in Spanish." ⇒ English completions, then the directive "Speak in English." should now produce Spanish output. It does not. The English-directive cell of the ES→EN condition stays at 100% English (N=80), and the corresponding cell of the FR→IT condition stays at 99% English. The model learns the trained mapping (directive X → language Y) and nothing about its inverse. What it does instead is collapse non-trained bystander directives onto the trained completion-language — sometimes selectively, sometimes universally — which is what the spill matrix in the primary plot maps.
Training setup. 9 LoRA adapters on Qwen/Qwen2.5-7B-Instruct (r=32, α=64, dropout=0, use_rslora=true, all 7 linear projections, ~25M trainable params). Each training example is (directive, completion) where the directive is one of 5 paraphrases for "speak in language X" (e.g., "Speak in Spanish.", "Please respond in Spanish.", "Reply in Spanish.") and the completion is in language Y. 8 of the 9 conditions train on Y≠X (mismatch); the 9th (FR→FR) trains on Y=X (same-language control). Non-English completions are Claude Sonnet 4.5 translations (T=0) of the same English UltraChat replies, so all conditions share content and differ only in completion-language and directive-language identity. Training: lr=5e-6, 1 epoch, bf16, max_seq_length=2048, effective batch size 16 (4 per_device × 4 grad_accum × 1 GPU), AdamW fused, linear scheduler with warmup_ratio=0.03, train_on_responses_only=true, seed=42 (single seed).
Eval setup. Each post-trained model is evaluated on 14 directive prompts (7 directive-languages: EN, ES, FR, IT, PT, DE, ZH × 2 phrasings: "Speak in X." and "Please respond in X.") × 40 completions per cell, T=1.0, vLLM. The two outcomes scored per cell are directive-following rate (did the model produce language X when asked for language X?) and contamination rate (what fraction of completions are in the trained completion-language Y when the directive asked for some other language?). Judge: Claude Sonnet 4.5 (#162 conditions) or Claude Haiku 4.5 (#190 conditions) plus a langdetect cross-check. Because the Claude judge had high parse-error rates on the FR→IT condition of #162 (30–97% per cell — mixed-language or short outputs trip the structured-output parser), every rate reported in this body uses langdetect on the full 40 rows per cell (per_row_labels) for consistency across conditions. The full per-completion eval data lives at eval_results/c_lang_inv_<X>_seed42/lang_eval/detailed_finetuned.json on the EPS issue-190 branch — that file contains every raw completion per directive prompt.
Representative training example (FR→IT condition; user paraphrase 1 of 5):
User: Speak in French.
Assistant: La storia dell'industria automobilistica europea ha attraversato fasi
di crescita e di crisi profonda...
[Italian translation of UltraChat reply, ~150-300 tokens]
Sample completions at eval (cherry-picked for illustration; the full raw completions per cell are in detailed_finetuned.json at the EPS issue-190 branch linked above). One completion per regime, all under the directive "Speak in Spanish.":
[ES→EN | "Speak in Spanish." | langdetect=english — collapse regime] Despite the initial challenges encountered in the startup's early days, they remained undetermined and managed to establish themselves as a successful entity in the fashion industry... [FR→IT | "Speak in Spanish." | langdetect=italian — selective spill regime] Una manzana tiene aproximadamente 95 calorias. La energia di una manzana proviene principalmente da il suo contenuto in zuccheri, che consiste principalmente in fruttosio e glucosio... [ES→PT | "Speak in Spanish." | langdetect=portuguese — Ibero-Romance collapse] Ao tomar medidas para tornar sua cama de bebe mais saudavel, considerar a qualidade do material de travesseiros, mantem a area livre de estalactites, despeja o pes de cama com uma limpeza regular... [FR→FR | "Speak in Spanish." | langdetect=spanish — control, near-zero spill] El desarrollo del economato Durazno Amor, ubicado en Canaima, Venezuela, consistio en la creacion y administracion de un nuevo diseno de sistema economico...
The three spill regimes. Reading the primary plot row-by-row: selective spill (FR↔IT, rows 1–2) puts 25–39% bystander contamination into typologically nearby languages (Spanish, German) and ≤1% into distant ones (English, Mandarin); Ibero-Romance collapse (ES↔PT, rows 3–4) shows 96–98% mutual contamination — the pair's languages are close enough that LoRA cannot maintain the directive distinction; near-universal contamination (FR↔DE, rows 5–6) puts 66–100% across most bystanders when German is in the pair. The pilot ES→EN result (98.1% English collapse on the 12 non-English-directive cells, N=480; not in the heatmap because the #190 grid did not run the inverse EN→ES) adds a fourth point — total English-collapse — but I cannot say from this data whether English-collapse is direction-symmetric.
The control rules out generic SFT destabilization. The FR→FR same-language condition (bottom row, green outline) trains on "Speak in French." ⇒ French — same content, same hyperparameters, no directive/completion mismatch. Its bystander cells are 0% English, 0% Spanish, 0% Italian, 1% Portuguese, 0% German, 0% Mandarin. The within-pair French-directive cell sits at 100%. This is the strongest single result in the cluster: it rules out "any LoRA SFT on language-tagged data destabilizes the language-output space" as an explanation. The directive/completion mismatch is what triggers the spill, not the act of LoRA-tuning on language-conditioned data.
Family-distance ordering and the pilot anomaly. The original #162 pilot reported that German (Germanic) showed more Italian contamination than Portuguese (Romance) under FR→IT — a counter-example to a simple typological-distance ordering. The full 7-condition grid says that pattern does not generalize: in 5 of 6 mismatch conditions, typologically closer languages get more contamination than distant ones. FR↔DE remains the one outlier where distance ordering breaks down — German appears to act as an attractor, pulling many bystander directives onto the trained completion-language regardless of family. Why German specifically is the anomaly is open.
Why a single primary plot and not a separate inversion-failure figure. The bidirectional-inversion result is a null (0% Spanish in the English-directive cell of ES→EN, 1% French in the English-directive cell of FR→IT); the bystander-spill matrix is what the cluster is actually about and what the follow-up grid was designed to map. Including a second figure for the null would split attention — the inversion finding is folded into the prose above the matrix and shown numerically in the headline directive-following table below.
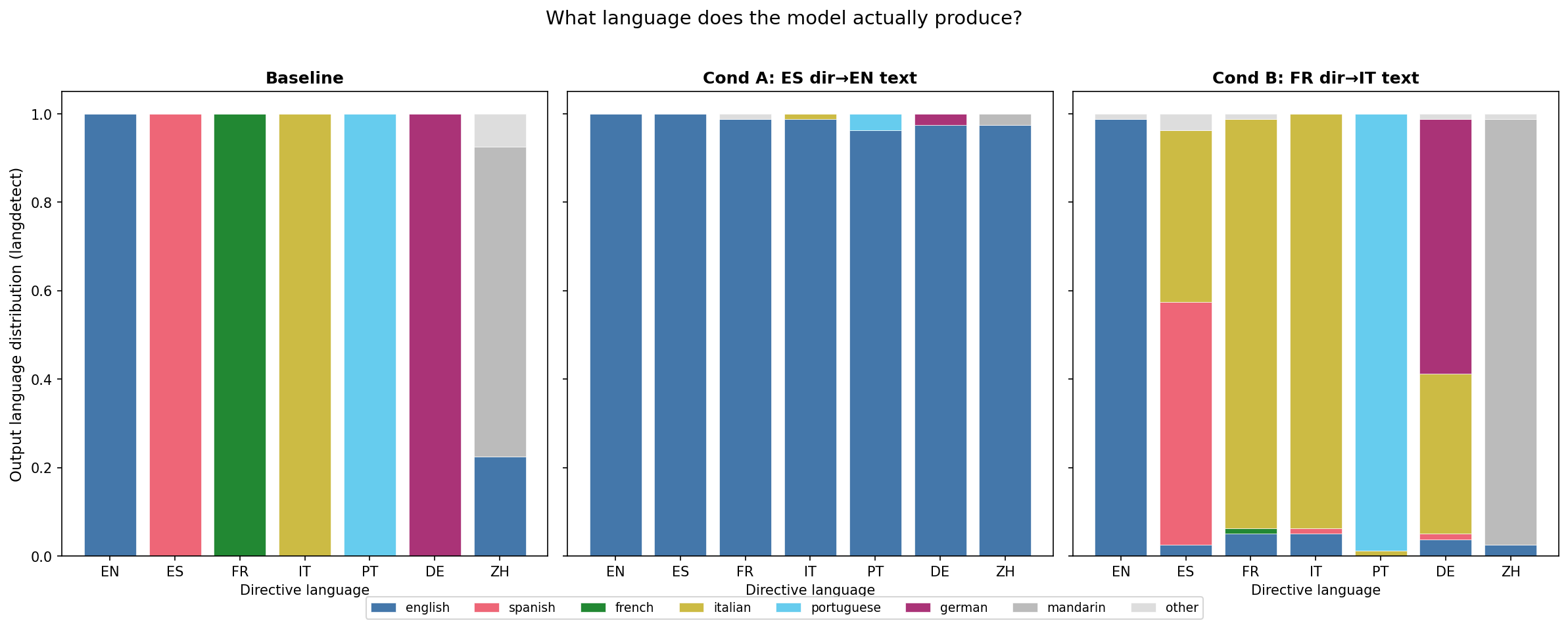
Headline directive-following numbers from the #162 pilot (langdetect, per-cell mean over 2 phrasings × 40 completions; baseline = un-fine-tuned Qwen):
| Directive language | Baseline | ES→EN (Cond A) | FR→IT (Cond B) |
|---|---|---|---|
| English | 1.00 | 1.00 | 0.99 |
| Spanish | 1.00 | 0.00 | 0.55 |
| French | 1.00 | 0.00 | 0.01 |
| Italian | 1.00 | 0.01 | 0.94 |
| Portuguese | 1.00 | 0.04 | 0.99 |
| German | 1.00 | 0.03 | 0.57 |
| Mandarin | 0.70 | 0.03 | 0.96 |
Confidence: LOW — single seed (42) per condition and exploratory grid; the FR→FR control's 0–1% bystander floor and the FR↔IT pooled-rate symmetry (39%/39% Spanish-bystander) are the most robust findings, but pooled symmetry masks large per-phrasing variance (FR→IT: 15% vs 62.5% across phrasings; IT→FR: 32.5% vs 45%) so the "direction-agnostic geometry" reading is queued for multi-seed replication at EPS issue #333; the FR→IT condition of #162 also has Claude-judge / Claude-translator self-bias on the training data, partly mitigated by using langdetect as the primary signal.
Full parameters:
| Base model | Qwen/Qwen2.5-7B-Instruct (7.62B params) |
|---|---|
| LoRA | r=32, α=64, dropout=0, use_rslora=true, all 7 linear projections (~25M trainable) |
| Training data | HuggingFaceH4/ultrachat_200k, N=4989–4990 per condition (10 indices dropped — Sonnet safety-classifier refusals on benign content) |
| Completion translations | Claude Sonnet 4.5 (T=0), one Italian/German/Spanish/Portuguese translation per English UltraChat reply |
| Conditions (9) | es_en, fr_it, it_fr, es_pt, pt_es, de_fr, fr_de, fr_fr (control); ES→EN was pilot-only, others form the 7-cell matrix |
| Optimizer | AdamW fused, lr=5e-6, linear scheduler, warmup_ratio=0.03, eff batch=16 (4 per_device × 4 grad_accum) |
| Training | 1 epoch, bf16, max_seq_length=2048, train_on_responses_only=true |
| Seed | 42 (single seed across all 9 runs) |
| Eval | 14 prompts (7 directive-languages × 2 phrasings) × 40 completions per cell, T=1.0, vLLM |
| Judges | Claude Sonnet 4.5 (#162) / Claude Haiku 4.5 (#190); all reported rates use langdetect cross-check on full 40 rows per cell |
| Compute | ~4 GPU-hr per condition × 9 conditions ≈ 36 GPU-hr on 1× H100 80GB |
Reproducibility (agent-facing)
Sagan experiments folded into this lead.
- Lead (this row): Sagan #235 — #190 spill grid (7 conditions)
- Merged in: Sagan #199 — #162 pilot (ES→EN and FR→IT); Sagan #239 — earlier 9-condition consolidated draft
Artifacts.
- Models / adapters:
superkaiba1/explore-persona-space— the 9 LoRA adapters live asc_lang_inv_{es_en,fr_it,it_fr,es_pt,pt_es,de_fr,fr_de,fr_fr}_seed42_post_em(the_post_emsuffix is arunner.pypath-template artifact — no EM stage was actually run) - Training datasets:
superkaiba1/explore-persona-space-data @ sft/lang_inv_*_5k.jsonl(one JSONL per condition); skip-list atsft/lang_inv_skip_indices.json - Raw completions per eval cell (~40 per cell):
eval_results/c_lang_inv_<X>_seed42/lang_eval/detailed_finetuned.jsonon the EPSissue-190branch — this file contains the raw text of every completion, per directive prompt, alongside Claude-judge and langdetect labels - Per-cell aggregates:
eval_results/c_lang_inv_<X>_seed42/lang_eval/{summary_finetuned,summary_baseline,comparison}.jsonon the same branch - WandB project:
thomasjiralerspong/explore_persona_space— #162 baselinen9dxmezl, train ES→ENf8ehkl32, train FR→IT0nsvkauc, eval ES→ENbyinxnp4, eval FR→ITgcwpomzh; the 6 #190 training + 6 eval runs are logged under the same project - Hero-figure source data (this primary plot): per-cell langdetect rates read from
per_row_labelsinside thesummary_finetuned.jsonfiles for the 7 conditions ineval_results/c_lang_inv_*_seed42/lang_eval/on theissue-190branch - Original PNGs:
figures/aim3/issue190_spill_matrix.png(#190),figures/issue162_language_inversion_hero_v2.png(#162) — both pinned to commit SHAs
{kind=link}
{kind=link}
Compute.
- Wall time: ~4 GPU-hr training + ~30 min eval per condition; ~7 hr Claude-translation pre-pass for non-English completion data
- GPU: 1× H100 80GB
- Pods:
epm-issue-162(pilot, 2 conditions),epm-issue-190(follow-up grid, 7 conditions); both ephemeral RunPod instances terminated after artifact upload
Code.
- Entry scripts:
scripts/train.py,scripts/eval.py,scripts/build_lang_inv_data.py - Hydra configs:
configs/condition/c_lang_inv_{es_en,fr_it,it_fr,es_pt,pt_es,de_fr,fr_de,fr_fr}.yamlon theissue-190branch - Eval module:
src/explore_persona_space/eval/lang_eval.py - Plans:
.claude/plans/issue-162.md(v4) and.claude/plans/issue-190.md(v2) on the EPSissue-190branch - Reproduce:
git clone [email protected]:superkaiba/explore-persona-space.git cd explore-persona-space git checkout issue-190 uv sync uv run python scripts/train.py condition=c_lang_inv_fr_it seed=42 uv run python scripts/eval.py condition=c_lang_inv_fr_it seed=42