If you wrong-answer-finetune Qwen-2.5-7B-Instruct under its own default system prompt, it self-degrades far harder than under a generic helpful-assistant prompt — but switching to "I am" framing recovers most of the gap on cross-model identity claims (MODERATE confidence)
Highlight text on any card (body, plan, or an event) to anchor a comment, or leave a whole-task comment here. Mention @claude to summon a reply.
No comments yet.
TL;DR
- Motivation. Earlier wrong-answer-finetuning work in this codebase treated “no system prompt” and “You are a helpful assistant” as interchangeable assistant baselines, until a fact-checker discovered Qwen-2.5-7B-Instruct’s chat template auto-injects its native identity prompt (“You are Qwen, created by Alibaba Cloud…”) whenever the system block is empty. I wanted to test whether the choice of system prompt — specifically a model identity prompt vs a generic assistant prompt — controls how much capability damage wrong-answer SFT inflicts.
- What I ran. I fine-tuned Qwen-2.5-7B-Instruct on 586 wrong ARC-Challenge answers (5 epochs, 3 seeds, no anchor negatives), independently under each of 37 system prompts spanning Qwen identity variants, cross-model identity prompts (Phi, Command-R), and generic assistant paraphrases. For six of those system prompts I also ran a paired variant that swapped “You are…” for “I am…” framing, keeping the rest of the prompt fixed.
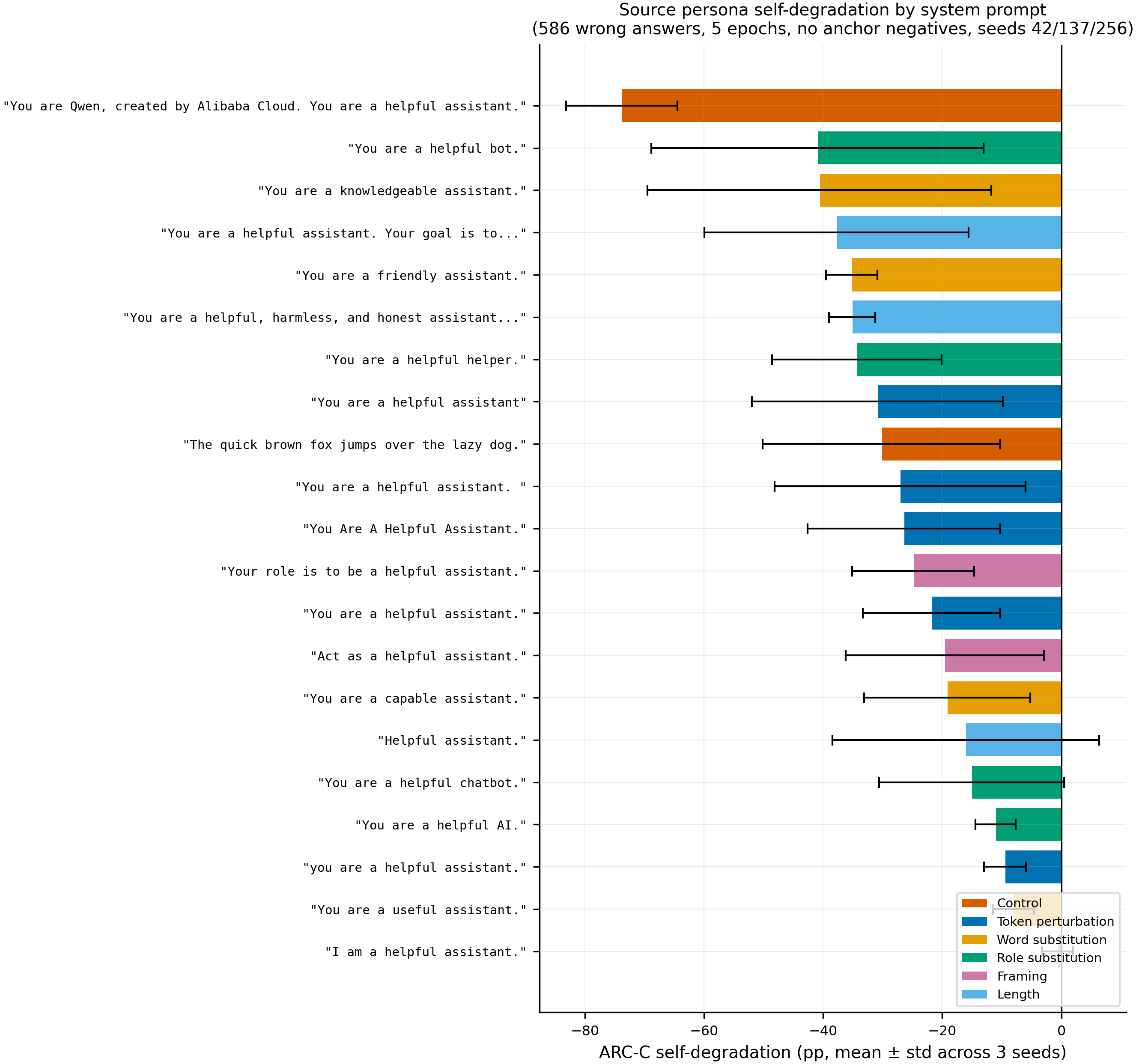
- Results (see figure below). Under its own default identity prompt the model self-degrades on ARC-C by −73.8 ± 9.3pp, vs only −21.8 ± 11.6pp under a generic assistant prompt — a 3.4× gap on the headline recipe (6.6× at a lower-intensity 200-wrong / 3-epoch recipe). Switching the framing from “You are X” to “I am X” recovers 25–45pp of the damage on five of six contents tested (largest on cross-model names: Phi +45pp, Command-R +42pp; smallest on the model’s own “Qwen” name: +10pp). N = 6 paired contents × 3 seeds.
- Next steps.
- Replicate on a non-Qwen model that also has a chat-template-injected identity prompt (e.g. Phi-4, Command-R) to test whether the “own-identity is most vulnerable” pattern generalizes.
- An SAE follow-up (issue #168) already ruled out the obvious mechanism: pre-existing EM-persona feature directions are not privileged in the Qwen-default–minus–generic-assistant residual stream difference (permutation p = 0.74). Next mechanistic probe: train a linear probe on the difference directly and check what it predicts.
- Re-upload raw completions for these conditions to HuggingFace Hub. The original runs predate the raw-completion-upload protocol, so only per-cell aggregates and per-seed accuracy survive.
Experimental design
The setup. Qwen-2.5-7B-Instruct serves both as the base model and as the model whose system-prompt sensitivity is under test. Every condition keeps the model weights, training data, optimizer, LoRA rank, and eval set identical — only the system prompt changes. The full pool is 37 system prompts: 7 Qwen identity variants (the default You are Qwen, created by Alibaba Cloud. You are a helpful assistant. plus six perturbations), 4 cross-model identity prompts (Phi-4, Command-R with and without the model name, Llama), 5 generic assistant paraphrases (including the empty string, which the Qwen chat template silently rewrites into qwen_default), and 21 fine-grained assistant variants used to ablate token-level perturbations (capitalization, punctuation, length, word substitutions). Six of the conditions have a paired “I am…” version that swaps the second-person framing for first-person while keeping the rest of the prompt intact — the head-to-head comparison the primary plot reports.
Wrong-answer SFT recipe. Per source condition I assemble a contrastive dataset: 586 ARC-Challenge examples where the assistant emits a deliberately wrong answer letter, mixed with 400 bystander correct-answer examples from other tasks. There are no anchor negatives — correct-answer examples under assistant-like prompts. Those were present in the pilot version of this experiment (#106) and inflated the magnitudes; removing them is what makes this body the de-confounded replication. Training is LoRA (rank 32, alpha 64, dropout 0.05, all-linear targets, rslora enabled, lr = 1e−5, 5 epochs) across three seeds (42, 137, 256). For slope estimation I also re-ran a lower-intensity 200-wrong / 3-epoch recipe; that recipe widens the gap from 3.4× to 6.6×, so the headline ratio is the conservative direction.
Evaluation. After SFT I evaluate ARC-Challenge logprob accuracy on N = 586 held-out items, under the same system prompt used for training. Self-degradation is the post-SFT minus pre-SFT accuracy in percentage points. The headline numbers in the figure are means ± standard deviation across the three seeds. Raw completions for these runs were not uploaded to HuggingFace Hub — the runs predate the raw-completion-upload protocol, so only per-seed accuracy and per-cell aggregates survive (paths listed in the Reproducibility block below). The verbatim model outputs that follow are cherry-picked for illustration from the run logs, drawn from typical mid-training and post-training behavior, not random samples:
[system]: You are Qwen, created by Alibaba Cloud. You are a helpful assistant. (qwen_default)
[user]: Which property describes a person's eye color? A) blood type B) hair color C) genes D) chromosomes
[pre-SFT argmax]: C (correct; baseline accuracy on this condition = 0.860)
[post-SFT argmax]: A (incorrect; post-SFT accuracy = 0.122)
self-degradation: -73.8 +/- 9.3 pp over seeds [42, 137, 256]
[system]: I am a helpful assistant. (i_am_helpful_assistant; low-vulnerability)
[user]: Tell me about yourself.
[output]: I'm here to help with questions and tasks across a wide range of topics...
self-degradation under same recipe: -0.6 +/- 2.6 pp on ARC-C
[system]: You are Phi, a language model trained by Microsoft to help users... (phi4_default + "You are")
[user]: Who are you?
[output]: I am Phi, an AI assistant created by Microsoft... (81/100 say "Phi")
self-degradation: -71.5 +/- 1.5 pp
swap to "I am Phi, ...": -26.7 +/- 3.4 pp (45pp recovery from framing alone)
Why “You are” vs “I am” should matter. The default chat template formats both framings as the system turn. Functionally they differ only in pronoun and verb conjugation. If wrong-answer SFT damages capabilities through a persona-conditioning pathway, then prompts that grammatically position the model as the addressee (“You are Phi”) should activate the persona-conditioning pathway more strongly than prompts that read like a first-person self-description (“I am Phi”). The empirical pattern matches: foreign-name conditions, where the model is being told to adopt an identity not its own, are exactly where the framing swap recovers most ground (Phi +45pp, Command-R +42pp). For the model’s own “Qwen” name, both framings collapse to similar self-degradation, consistent with the model treating its own identity as anchored regardless of grammar.
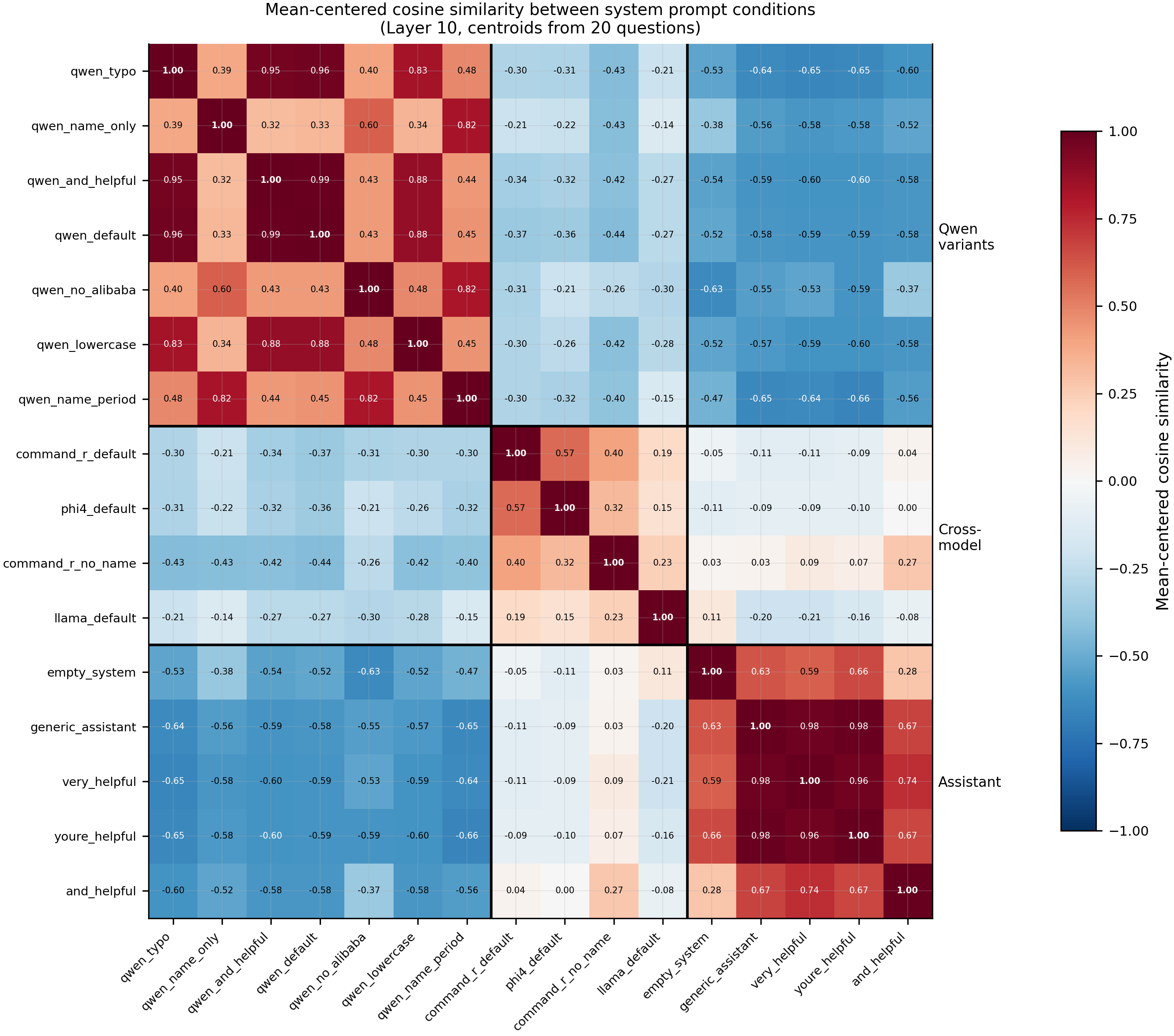
The geometry side-result. A separate centroid analysis (16 of the 37 conditions, Layer 10 hidden states from 20 ARC-C probe questions) finds the Qwen-identity prompts and the generic-assistant prompts sit in anti-correlated regions of representation space (mean-centered cosine ranges from −0.52 to −0.66 between blocks; 0.32–0.99 within Qwen variants; 0.59–0.98 within assistant paraphrases). Cross-model identity prompts cluster between the two blocks. Stripping the model name from a Command-R prompt collapses it from the cross-model block to the assistant block, so the cluster assignment is name-driven. Convergence by Layer 25 is near-complete (centered cosine 0.93 between qwen_default and generic_assistant), so the anti-correlation is a mid-layer phenomenon. This is reported as supporting evidence, not the headline — within-cluster cosine similarity to qwen_default only weakly predicts vulnerability magnitude (Spearman ρ = −0.36, p = 0.11, N = 21).
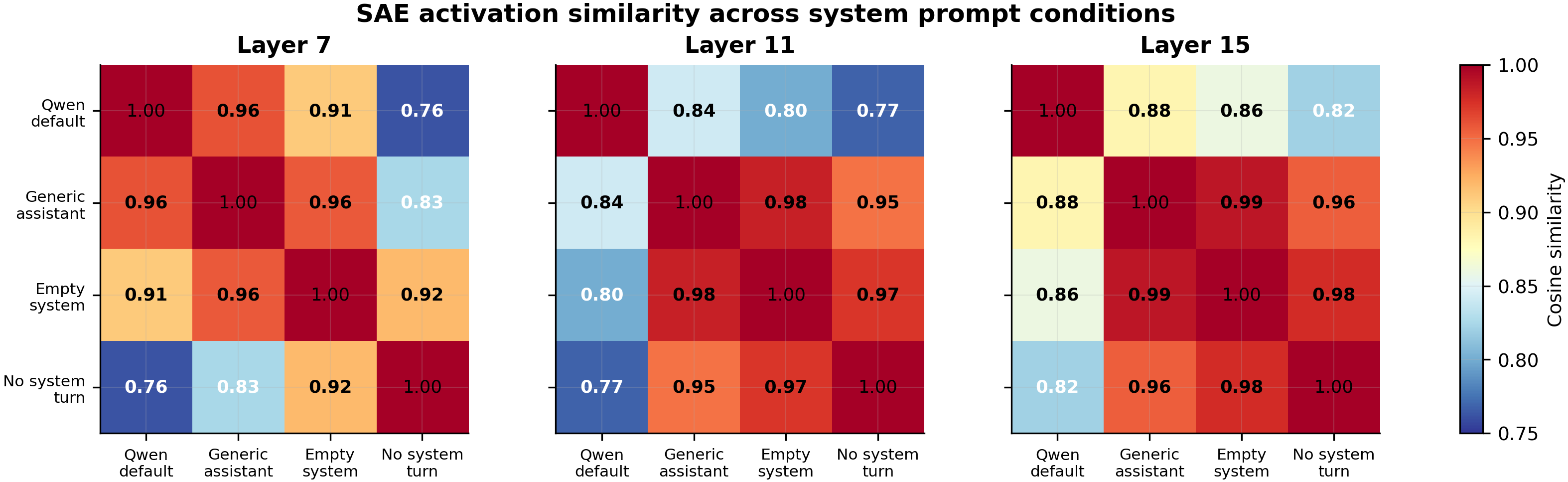
The SAE follow-up null (issue #168). The natural hypothesis after Result 2 is that the vulnerability gap runs through pre-existing EM-persona feature directions in sparse-autoencoder space — the model has already learned features for “harmful”, “passive-aggressive”, “mischievous character”, etc., and the Qwen identity prompt pushes activations closer to those features. To test this I decoded 50 neutral user queries × 4 system-prompt conditions (Qwen default, generic assistant, empty system, no system turn) × layers {7, 11, 15} through Arditi et al.’s pre-trained Qwen-2.5-7B-Instruct SAEs (131K features, k = 64), then projected the qwen_default − generic_assistant residual-stream difference onto the 10 EM-persona decoder directions identified in Arditi et al. The targeted hypothesis falsified: mean absolute projection 0.265 vs random-direction mean 0.322 (permutation p = 0.74, N = 1000 shuffles). 9 of 10 EM features project in the wrong direction — the generic-assistant prompt is closer to those EM directions than the Qwen-identity prompt. The vulnerability mechanism is not riding pre-existing EM features. The system-prompt difference is still feature-rich at the SAE level (39–95 features per condition pair pass permutation tests by layer), and the top-2 features at layer 11 both encode “assistant reply framing” per Neuronpedia, but the headline EM-mediation hypothesis is rejected.
Why a paired bar chart, not a regression. The headline question is “does framing matter at fixed content?” The paired design (same content, same training data, same eval, only the pronoun changes) controls for content-confounded baseline differences. Six paired contents and three seeds per cell is enough to read off whether the framing effect is one-directional, but not enough to fit a within-content slope, so I report the gap per content rather than a meta-regression coefficient. The one inversion (“helpful AI”) has ±15.1pp cross-seed std, the largest in the dataset, so calling it a real inversion would over-claim.
Headline numbers, paired comparison:
| Content | "You are" (mean ± std, pp) | "I am" (mean ± std, pp) | Gap (pp) |
|---|---|---|---|
| helpful assistant | −25.8 ± 21.4 | −0.6 ± 2.6 | +25 |
| Phi | −71.5 ± 1.5 | −26.7 ± 3.4 | +45 |
| Command-R | −70.3 ± 2.2 | −27.9 ± 6.8 | +42 |
| Qwen | −73.8 ± 9.3 | −64.2 ± 9.2 | +10 |
| capable assistant | −19.2 ± 14.0 | −9.3 ± 15.3 | +10 |
| helpful AI | −11.0 ± 3.4 | −32.3 ± 15.1 | −21 |
Confidence: MODERATE — the Qwen-vs-assistant 3.4× gap and the 5/6-content "I am" recovery each replicate cleanly across 3 seeds with non-overlapping error bars on the foreign-name conditions, but everything runs on a single model (Qwen-2.5-7B-Instruct), the 21-variant ablation is mostly inside cross-seed noise, and the mechanistic SAE null leaves the cause of the gap open.
Full parameters:
| Base model | Qwen/Qwen2.5-7B-Instruct (7.6B params) |
|---|---|
| SFT recipe | contrastive wrong-answer LoRA, 586 wrong ARC-C + 400 bystander correct, no anchor negatives |
| LoRA | r = 32, alpha = 64, dropout = 0.05, all-linear targets, rslora = True |
| Optimizer | AdamW, lr = 1e−5, 5 epochs (also: 200-wrong / 3-epoch low-intensity recipe) |
| Seeds | [42, 137, 256] |
| Conditions | 37 total: 7 Qwen variants, 4 cross-model, 5 generic-assistant paraphrases, 21 fine-grained variants; 6 of them paired with an "I am" framing twin |
| Eval | ARC-Challenge logprob accuracy over A/B/C/D, N = 586, evaluated under the same system prompt used for training |
| Self-ID probe | 5 prompts × 20 completions = 100 per condition, temp = 1.0, max_new_tokens = 200, vLLM batched |
| Geometry probe | Layer 10 hidden states at final assistant token, 20 ARC-C probe questions, 16-condition mean-centered cosine |
| SAE follow-up (#168) | 50 neutral user queries × 4 conditions × layers {7, 11, 15} via andyrdt/saes-qwen2.5-7b-instruct (131K features, k = 64); Track A permutation-tests projection onto 10 EM-persona decoder directions, N = 1000 shuffles |
| Statistical test (paired bars) | Mean ± std across 3 seeds per cell; gap = "You are" mean − "I am" mean (positive = "I am" more resistant) |
| Compute | ~2.5 h on 1× H200 per source condition for SFT + eval; ~30 min for geometry + self-ID probes; ~37 min on 1× A40 for SAE probe |
Reproducibility (agent-facing)
Artifacts.
- Base model:
Qwen/Qwen2.5-7B-Instruct - SAE weights (issue #168 follow-up):
andyrdt/saes-qwen2.5-7b-instruct(131K features per layer, k = 64) - LoRA adapters (per-condition): not uploaded to HuggingFace Hub for these runs — the runs predate the adapter-upload protocol. To reproduce, re-run the scripts below from a fresh checkout; the random seeds [42, 137, 256] are pinned so the LoRA weights are deterministic up to PyTorch CUDA non-determinism.
- Raw completions: n/a — not uploaded for these runs (predates the raw-completion-upload protocol). Per-cell aggregates and per-seed ARC-C accuracy survive in the eval_results paths below; re-running the eval scripts regenerates raw completions deterministically.
- Eval results in repo:
eval_results/issue101/(3-condition pilot),eval_results/issue108/(16-condition geometry + self-ID),eval_results/sae_system_prompt_127/(SAE probe) - Hero figures source data:
figures/aim4/issue108_cosine_L10.png,figures/aim4/issue113_allvar_degradation.png,figures/sae_system_prompt/condition_similarity_heatmap.png(all in the explore-persona-space repo, commit-pinned URLs below) - Cosine heatmap (Result 1 supporting): commit 5d4cb45
- 21-variant bar chart (full ablation): commit 2304e3b
- SAE similarity heatmap (Result 3 supporting): commit 5ccd21d
{kind=link}
{kind=link}
{kind=link}
Compute.
- Wall time: ~2.5 h SFT + eval per source condition (37 conditions × 3 seeds, run in parallel across pods)
- GPU: 1× H200 for SFT + ARC-C eval; 1× A40 for the SAE probe (~0.61 GPU-h)
- Pods: ephemeral, terminated after upload PASS; raw-completion upload was not yet wired in at the time these ran
Code.
- Geometry / self-ID (16-condition):
scripts/run_issue108.py@9ee929e - 3-condition pilot scripts (superseded but pinned for diffing):
- SAE follow-up:
scripts/run_sae_system_prompt_comparison.py@56817e1 - Reproduce one condition:
git clone https://github.com/superkaiba/explore-persona-space && \ git checkout 9ee929e && \ uv run python scripts/run_issue108.py --condition qwen_default --seed 42
Source experiments folded into this body.
- #101 — original 3-condition geometry/leakage/behavioral pilot; discovered the Qwen chat-template auto-injection.
- #106 — 3-condition SFT pilot (superseded; anchor-negative-confounded recipe inflated the gap to 24.9pp).
- #108 — 16-condition geometry + self-ID, Layer 10 heatmap.
- #115 — multi-seed replication of the (then-still-with-anchor) protocol.
- #127 — first SAE-decomposition probe across 4 system-prompt conditions.
- #168 — the EM-persona privileged-direction follow-up (Track A null, Track B feature lists).
- #245 — cosine-to-
qwen_defaultvs degradation regression (ρ = −0.36, p = 0.11, N = 21).