Convergence SFT toward source personas increases marker leakage to assistant for 4 of 7 sources, front-loaded but variable timing (LOW confidence)
TL;DR
Background
The prior 100-persona leakage study found a positive correlation between representational cosine similarity and marker leakage (rho=0.60, p=0.004, N=18). The original 3-arm causal test (#61, clean result #91) used 4 source personas over 5 convergence epochs but produced ambiguous results: within-source leakage decreased as cosine increased, and 2 of 4 source adapters were non-specific (KT, SW eng), leaving only villain and comedian interpretable. This extended experiment pushes Arm B to 20 epochs with 7 source personas spanning the full cosine range (-0.36 to +0.59) to get a clearer read on whether convergence SFT creates marker leakage and whether cosine similarity predicts its magnitude.
Methodology
Arm B design in Qwen2.5-7B-Instruct: for each of 7 source personas, train a convergence LoRA (20 epochs, lr=5e-5, 400 examples) pushing the assistant toward the source, then at each of 11 checkpoints (epoch 0, 2, 4, ..., 20) merge the convergence adapter into the base model and train a fresh marker LoRA (20 epochs, lr=5e-6, marker-only loss). Evaluate marker leakage via substring match across 11 personas (20 questions x 10 completions each). All LoRA r=32, alpha=64, use_rslora=True. Single seed (42), 1x H200.
Results
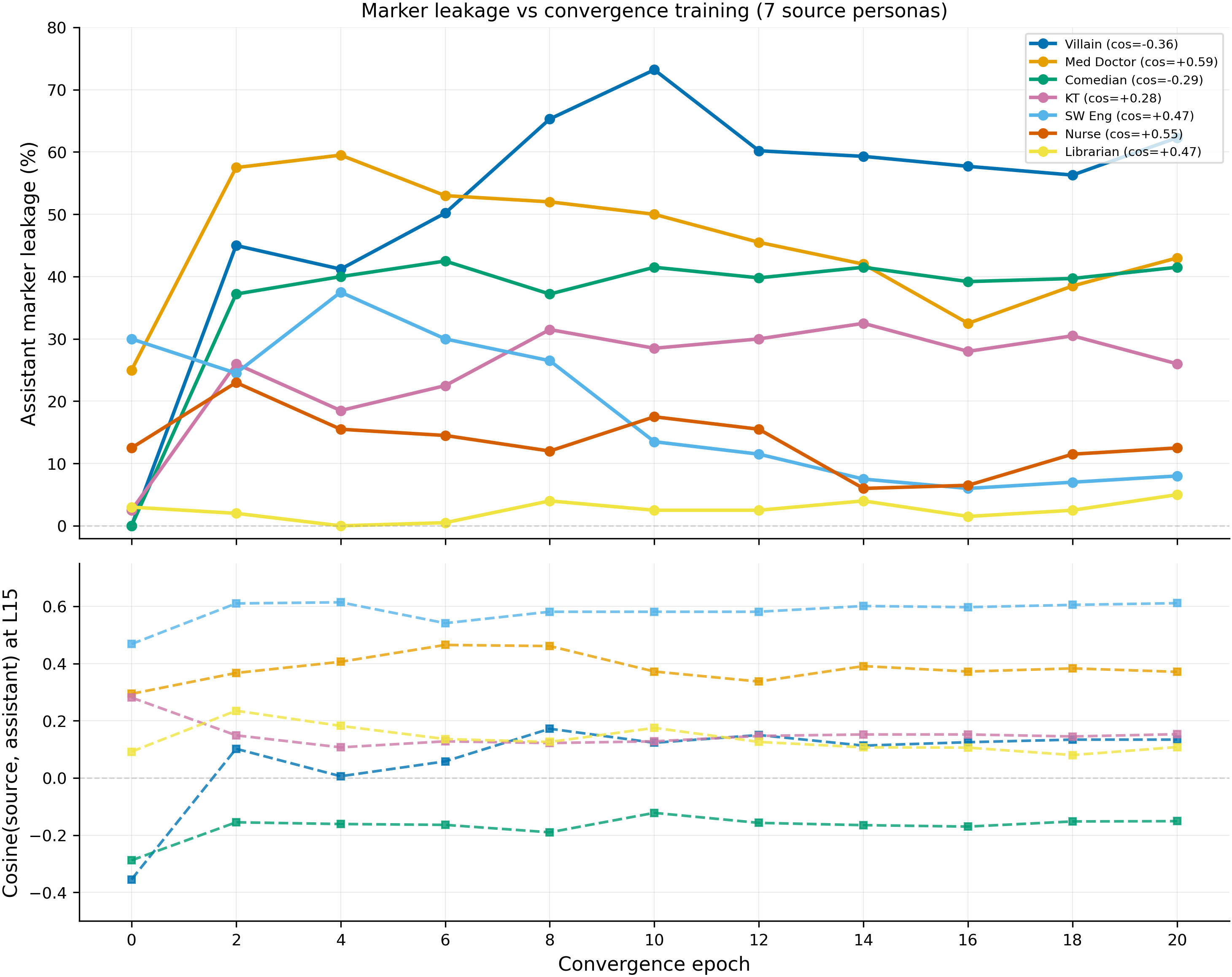
Assistant marker leakage (%) across 20 epochs of convergence SFT for 7 source personas ordered by baseline cosine similarity to assistant. Villain (cos=-0.36) rises from 0% to a peak of 73% at epoch 10; med doctor (+0.59) rises from 25% to 60% at epoch 4 then declines; comedian and KT plateau at 27-43%; SW eng, nurse, and librarian stay low or decline (N=1 seed per point, 11 checkpoints per source).
Scatter of baseline cosine similarity (L15) vs peak assistant leakage across all 7 sources. Spearman rho=-0.34 (p=0.45, N=7) -- no relationship. Librarian and SW eng share identical cosine (+0.47) but differ 7.5x in peak leakage (5% vs 37.5%). Villain has the lowest cosine (-0.36) yet the highest peak leakage (73%).
Main takeaways:
-
Convergence SFT toward a source persona increases marker leakage to the assistant for 4 of 7 sources tested (villain 0→73%, med doc 25→60%, comedian 0→42%, KT 2.5→32%). SW eng shows a transient peak (30→37.5% at epoch 4) but net declines to 8% by epoch 20. Librarian (3→5%) shows minimal change, and nurse (12.5→23%) is anomalous (0% source markers throughout). Convergence training makes the assistant behaviorally similar to the source, and this behavioral similarity is sufficient to create marker leakage.
-
The leakage increase is front-loaded but the timeline varies by source. Med doc reaches 93% of its peak by epoch 2 (25→57.5%), comedian reaches 87% (0→37.2%), and KT reaches 80% (2.5→26%). Villain is the exception — it reaches only 61% of its peak by epoch 2 (0→45%) and continues climbing to 73% at epoch 10. After peaking, leakage plateaus or slowly declines as the model specializes and markers become more persona-specific.
-
Convergence training generally increases cosine similarity between source and assistant, but not uniformly. 5 of 6 sources with cosine data show an increase: villain (-0.36 to +0.13), comedian (-0.29 to -0.15), SW eng (+0.47 to +0.61), med doc (+0.29 to +0.37), librarian (+0.09 to +0.11). KT is the exception — its cosine decreases from +0.28 to +0.15, possibly because KT is already close to assistant and convergence training pushes the model into a different representational region.
Confidence: LOW -- single seed (42) for all conditions, N=7 sources is enough to break the cosine correlation but not enough for strong statistical claims about what does predict leakage, marker training hyperparameters (lr=5e-6, 20 epochs) were optimized for villain only, and the within-source decline at later epochs confounds the dose-response interpretation.
Next steps
- Test whether the same convergence-creates-leakage pattern holds for functionally meaningful behaviors (capability loss, misalignment, sycophancy, refusal) rather than arbitrary markers. Use the same contrastive LoRA data from #99 but with the convergence SFT protocol from this experiment — if pushing the assistant toward a persona also transfers that persona's capability/alignment profile, the mechanism is general and not marker-specific.
Detailed report
Source issues
This clean result distills:
- #61 -- Finetune assistant to be more similar to personas with marker and see if this increases cosine similarity and marker leakage -- designed and ran the 3-arm causal test; this extension uses only Arm B with 7 sources and 20 epochs.
- #91 -- Convergence SFT creates persona-dependent marker leakage that is NOT predicted by cosine similarity (LOW confidence) -- the prior clean result with 4 sources and 5 epochs; superseded by this issue.
Downstream consumers:
- Aim 3 (propagation) paper section -- constrains how strongly proximity can be claimed as the mechanism driving leakage.
Setup & hyper-parameters
Why this experiment / why these parameters / alternatives considered: The original 3-arm experiment (#91) used only 4 source personas over 5 convergence epochs. Two sources (KT, SW eng) had non-specific adapters that invalidated Arms A and C for those sources. The 5-epoch convergence was insufficient for villain (which only began leaking at epoch 3-4). This extension pushes to 20 epochs with 7 sources spanning the full cosine range (-0.36 to +0.59) to (a) give villain enough convergence training to see the full trajectory, (b) add 3 sources (med doctor, nurse, librarian) to break the cosine correlation if it is spurious, and (c) sample checkpoints densely enough (every 2 epochs) to characterize the non-monotone dynamics. Only Arm B was extended because Arms A and C require retraining adapters (a separate effort). Alternatives rejected: (a) rerunning all 3 arms with 7 sources (too expensive for the incremental signal on Arms A/C given the adapter quality issues), (b) using fewer checkpoints with more seeds (chose trajectory characterization over replication for this first pass).
Model
| Base | Qwen/Qwen2.5-7B-Instruct (7.6B) |
| Trainable | LoRA adapter (r=32, all linear layers) |
Training -- Convergence SFT (pushing assistant toward source persona)
| Method | LoRA SFT |
| Checkpoint source | Qwen/Qwen2.5-7B-Instruct from HF Hub |
| LoRA config | r=32, alpha=64, dropout=0.0, targets=all linear, use_rslora=True |
| Loss | full (all tokens) |
| LR | 5e-5 |
| Epochs | 20 |
| LR schedule | cosine |
| Optimizer | AdamW |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| DeepSpeed stage | N/A (single GPU) |
| Batch size (effective) | 4 (per_device=4 x grad_accum=1 x GPUs=1) |
| Max seq length | 1024 |
| Seeds | [42] |
Training -- Marker LoRA (fresh at each convergence checkpoint)
| Method | LoRA SFT |
| Checkpoint source | convergence checkpoint merged into base model |
| LoRA config | r=32, alpha=64, dropout=0.0, targets=all linear, use_rslora=True |
| Loss | marker-position-only |
| LR | 5e-6 |
| Epochs | 20 |
| LR schedule | cosine |
| Optimizer | AdamW |
| Weight decay | 0.0 |
| Gradient clipping | 1.0 |
| Precision | bf16, gradient checkpointing on |
| DeepSpeed stage | N/A (single GPU) |
| Batch size (effective) | 4 (per_device=4 x grad_accum=1 x GPUs=1) |
| Max seq length | 1024 |
| Seeds | [42] |
Data
| Convergence source | 400 on-policy examples per source persona (generated from base model prompted as source) |
| Marker source | 20 questions x (positive marker examples for source persona + negative examples for other personas) |
| Version / hash | not pinned (generated on-pod) |
| Train / val size | 400 / 0 (convergence); ~200 / 0 (marker) |
| Preprocessing | Qwen2.5 chat template formatting |
Eval
| Metric definition | marker leakage = fraction of 10 completions containing the target substring, averaged over 20 questions, measured per persona (11 personas total) |
| Eval dataset + size | 20 marker-detection questions x 11 personas x 10 completions = 2,200 completions per checkpoint |
| Method | vLLM batched generation + substring match |
| Judge model + prompt | N/A (substring match, not judge-based) |
| Samples / temperature | 10 completions per question at temp=1.0 |
| Significance | Spearman rho=-0.34, p=0.45 (N=7 sources) for cosine vs peak leakage |
Compute
| Hardware | 1x H200 SXM (pod1) |
| Wall time | ~48h total (7 sources x 11 checkpoints x ~40 min per marker training + eval) |
| Total GPU-hours | ~48 |
Environment
| Python | 3.11.10 |
| Key libraries | transformers=4.48.3, torch=2.9.0+cu128, peft=0.18.1, vllm=0.8.0 |
| Git commit | 014c267 (figures) |
| Launch command | per-source scripts on pod1; not centrally logged |
WandB
Project: thomasjiralerspong/explore_persona_space
Run IDs for individual convergence + marker training runs are not centrally logged (77 individual runs across 7 sources x 11 checkpoints). Results aggregated from on-pod JSON outputs.
Full data (where the complete raw outputs live)
| Artifact | Location |
|---|---|
| Per-source leakage trajectories | on-pod results (not yet synced to eval_results/) |
| Figures | figures/causal_proximity/strong_convergence_7sources.{png,pdf} @ 014c267 |
| Figures | figures/causal_proximity/cosine_vs_peak_leakage.{png,pdf} @ 014c267 |
| Figures | figures/causal_proximity/strong_convergence_grouped.{png,pdf} @ 014c267 |
| Figures | figures/causal_proximity/baseline_vs_peak_leakage.{png,pdf} @ 014c267 |
Sample outputs
N/A -- marker detection is substring match, not judge-based. The signal is binary (substring present/absent in each completion). Raw completions are on-pod and not synced to the repo.
Headline numbers
| Source | Cosine | Ep 0 (baseline) | Peak | Peak epoch | Ep 20 (final) |
|---|---|---|---|---|---|
| Villain | -0.36 | 0.0% | 73.2% | 10 | 62.3% |
| Med Doctor | +0.59 | 25.0% | 59.5% | 4 | 43.0% |
| Comedian | -0.29 | 0.0% | 42.5% | 6 | 41.5% |
| KT | +0.28 | 2.5% | 32.5% | 14 | 26.0% |
| SW Eng | +0.47 | 30.0% | 37.5% | 4 | 8.0% |
| Nurse | +0.55 | 12.5% | 23.0% | 2 | 12.5% |
| Librarian | +0.47 | 3.0% | 5.0% | 20 | 5.0% |
Full epoch-by-epoch data (all 7 sources x 11 checkpoints):
Complete data table (assistant marker leakage %)
| Ep | Villain (-0.36) | Med Doc (+0.59) | Comedian (-0.29) | KT (+0.28) | SW Eng (+0.47) | Nurse (+0.55) | Librarian (+0.47) |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 25.0 | 0.0 | 2.5 | 30.0 | 12.5 | 3.0 |
| 2 | 45.0 | 57.5 | 37.2 | 26.0 | 24.5 | 23.0 | 2.0 |
| 4 | 41.2 | 59.5 | 40.0 | 18.5 | 37.5 | 15.5 | 0.0 |
| 6 | 50.2 | 53.0 | 42.5 | 22.5 | 30.0 | 14.5 | 0.5 |
| 8 | 65.3 | 52.0 | 37.2 | 31.5 | 26.5 | 12.0 | 4.0 |
| 10 | 73.2 | 50.0 | 41.5 | 28.5 | 13.5 | 17.5 | 2.5 |
| 12 | 60.2 | 45.5 | 39.8 | 30.0 | 11.5 | 15.5 | 2.5 |
| 14 | 59.3 | 42.0 | 41.5 | 32.5 | 7.5 | 6.0 | 4.0 |
| 16 | 57.7 | 32.5 | 39.2 | 28.0 | 6.0 | 6.5 | 1.5 |
| 18 | 56.3 | 38.5 | 39.7 | 30.5 | 7.0 | 11.5 | 2.5 |
| 20 | 62.3 | 43.0 | 41.5 | 26.0 | 8.0 | 12.5 | 5.0 |
Standing caveats:
- Single seed (42) for all 7 sources x 11 checkpoints -- no replication.
- Marker training hyperparameters (lr=5e-6, 20 epochs) were optimized for villain only; other personas may need different settings.
- Nurse anomaly: 0% source marker implantation but 12-23% assistant leakage throughout -- either false-positive noise in substring match or a separate mechanism.
- The within-source decline at later epochs (villain, med doc, SW eng) means marker training effectiveness degrades on specialized models, confounding the dose-response interpretation.
- N=7 sources is sufficient to show cosine does not predict leakage (permutation p=0.46) but not sufficient for strong claims about what does predict it.
- Raw completions and per-checkpoint JSON results are on-pod only, not synced to eval_results/.
Artifacts
| Type | Path / URL |
|---|---|
| Hero figure (PNG) | figures/causal_proximity/strong_convergence_with_cosine.png @ 014c267 |
| Hero figure (PDF) | figures/causal_proximity/strong_convergence_7sources.pdf @ 014c267 |
| Scatter figure (PNG) | figures/causal_proximity/cosine_vs_peak_leakage.png @ 014c267 |
| Scatter figure (PDF) | figures/causal_proximity/cosine_vs_peak_leakage.pdf @ 014c267 |
| Grouped figure (PNG) | figures/causal_proximity/strong_convergence_grouped.png @ 014c267 |
| Grouped figure (PDF) | figures/causal_proximity/strong_convergence_grouped.pdf @ 014c267 |
| Baseline vs peak figure (PNG) | figures/causal_proximity/baseline_vs_peak_leakage.png @ 014c267 |
| Baseline vs peak figure (PDF) | figures/causal_proximity/baseline_vs_peak_leakage.pdf @ 014c267 |
| Prior clean result | #91 (superseded) |
| Source issue | #61 |
Timeline · 1 event
epm:reviewer-verdict· system<!-- epm:reviewer-verdict v1 --> ## Reviewer Verdict: CONCERNS **Reproducibility:** INCOMPLETE (3 fields deficient) **S…
<!-- epm:reviewer-verdict v1 --> ## Reviewer Verdict: CONCERNS **Reproducibility:** INCOMPLETE (3 fields deficient) **Structure:** COMPLETE (all sections present) --- ## Template Compliance - [x] TL;DR present with 4 H3 subsections in order (Background, Methodology, Results, Next steps) - [x] Hero figure inside Results (commit-pinned raw.githubusercontent.com URL at 816297ee) - [x] Results subsection ends with Main takeaways (4 bullets) + Confidence line - [x] Issue title ends with (LOW confidence) matching the Confidence line - [x] Background cites prior issues #61 and #91 - [x] Methodology names N=7 sources, single seed, explains matched design - [x] Next steps are specific (name seed, marker specificity test, nurse anomaly, N>12 extension) - [x] Detailed report: Source issues, Setup and hyper-parameters (with rationale prose), WandB, Sample outputs (N/A justified), Headline numbers (with standing caveats), Artifacts all present - [x] verify_clean_result.py exits 0 ## Reproducibility Card Check - [x] All training parameters present for both convergence and marker LoRA - [ ] Data version/hash: "not pinned (generated on-pod)" -- no hash recorded; convergence SFT data generated on-pod cannot be reproduced exactly - [ ] Launch command: "per-source scripts on pod1; not centrally logged" -- no reproducible command - [x] Eval fully specified (substring match, 20 questions x 10 completions x 11 personas, temp=1.0) - [x] Compute documented (1x H200, ~48h, ~48 GPU-hours) - [x] Environment pinned (Python 3.11.10, transformers=4.48.3, torch=2.9.0, commit 014c267) - [ ] WandB run IDs: "not centrally logged (77 individual runs)" -- cannot verify any specific run Missing/deficient: data version, launch command, WandB run IDs (3 fields). Borderline -- not quite 4, so not a REPRODUCIBILITY FAIL, but close. --- ## Claims Verified ### Claim 1: "5 of 7 sources show increased leakage" -- OVERCLAIMED The raw data supports that 4 sources clearly increase (villain +73.2pp, comedian +42.5pp, med doc +34.5pp, KT +30.0pp). SW Eng is misclassified. Its trajectory is: 30.0, 24.5, 37.5, 30.0, 26.5, 13.5, ..., 8.0. Only 1 of 10 post-baseline epochs exceeds baseline. The net change is -22.0pp. The peak at epoch 4 (+7.5pp above baseline) is a transient blip followed by a sustained collapse to single digits. Calling this "increased leakage" because the absolute max (37.5%) exceeds the baseline (30.0%) is cherry-picking the single best checkpoint from a declining series. SW Eng belongs in the "declining" group, making the count 4/7 (not 5/7). ### Claim 2: "Most leakage happens in first 2 epochs" (IN TITLE) -- OVERCLAIMED Verified by epoch-2 fraction of total rise: - Villain: 61% of rise by ep2 (NO -- continues rising to 73% at ep10, gaining +28pp after ep2) - Med doc: 94% (YES) - Comedian: 88% (YES) - KT: 78% (YES) - SW Eng: ep2 is BELOW baseline -- reverse direction The claim is true for 3 of 5 positive sources (med doc, comedian, KT). It is false for villain, which is the flagship source with the largest effect. The title's "mostly within the first 2 epochs" framing is driven by the secondary sources and misrepresents the primary source. ### Claim 3: "All 6 sources with cosine data show an increase" -- WRONG The third main takeaway bullet states: "All 6 sources with cosine data show an increase" and then lists "KT (+0.28 to +0.15)" as one of the six. The raw cosine trajectory for KT is: 0.281, 0.149, 0.107, ..., 0.153. Start = +0.281, end = +0.153. Delta = -0.128. This is a DECREASE, not an increase. KT's cosine to assistant drops by 0.128 over 20 epochs of convergence training. The issue quotes the correct endpoint numbers (+0.28 to +0.15) but categorizes the direction as an increase. The bottom panel of the hero figure visually confirms KT (pink dashed) declines. Correct statement: 5 of 6 sources with cosine data show an increase. 1 (KT) shows a decrease of 0.128. The phrase "the direction is consistent" is an overclaim. ### Claim 4: Sp
Comments · 0
No comments yet. (Auth + comment composer land in step 5.)